Introduction
![]()
![]()
![]()
Simple IoT enables you to add remote sensor data, telemetry, configuration, and device management to your project or product.
Implementing IoT systems is hard. Most projects take way longer and cost more than they should. The fundamental problem is getting data from remote locations (edge) to a place where users can access it (cloud). We also need to update data and configuration at the edge in real time from any location. Simple IoT is an attempt to solve these problems by embracing the fact that IoT systems are inherently distributed and building on simple concepts that scale.
Simple IoT provides:
- A single application with no dependencies that can be run in both cloud and edge instances
- efficient synchronization of data in both directions
- A flexible UI to view configuration and current values
- A rules engine that runs on all instances that can trigger notifications or set data
- Extensive support for Modbus - both server and client
- Support for the Linux 1-wire subsystem.
- flexible graph organization of instances, users, groups, rules, and configuration
- Integration with other services like InfluxDB, Victoria Metrics, and Twilio
- A system that is easy to extend in any language using NATS
- A number of useful Go packages to use in your custom application
See vision, architecture, and integration for addition discussion on these points.
See detailed documentation for installation, usage, and development information.
Motivation
This project was developed while building real-world IoT applications and has been driven by the following requirements:
- Data (state or configuration) can be changed anywhere — at edge devices or in the cloud and this data needs to be synchronized seamlessly between instances. Sensors, users, rules, etc. can all change data. Some edge systems have a local display where users can modify the configuration locally as well as in the cloud. Rules can also run in the cloud or on edge devices and modify data.
- Data bandwidth is limited in some IoT systems — especially those connected with Cat-M modems (< 100Kb/sec). Additionally, connectivity is not always reliable, and systems need to continue operating if not connected.
Core ideas
The process of developing Simple IoT has been a path of reducing what started as a fairly complex IoT system to simpler ideas. This is what we discovered along the way:
- Treat configuration and state data the same for purposes of storage and synchronization.
- Represent this data using simple types (Nodes and Points).
- Organize this data in a graph.
- All data flows through a message bus.
- Run the same application in the cloud and at the edge.
- Automatically sync common data between instances.
Design is the beauty of turning constraints into advantages.
- Ava Raskin
These constraints have resulted in Simple IoT becoming a flexible distributed graph database optimized for IoT datasets. We’ll explore these ideas more in the documentation.
Support, Community, Contributing, etc.
Pull requests are welcome - see development for more thoughts on architecture, tooling, etc. Issues are labeled with “help wanted” and “good first issue” if you would like to contribute to this project.
For support or to discuss this project, use one of the following options:
- Documentation
- Simple IoT community forum
- #simpleiot Slack channel is available on gophers.slack.com
- Open a GitHub issue
- Simple IoT YouTube channel
- Subscribe to our email newsletter for project updates.
If you use this project, please let us know! It is really helpful to hear from users.
License
Apache Version 2.0
Contributors
Thanks to contributors:
Made with contrib.rocks.
Installation
Simple IoT will run on the following systems:
- ARM/x86/RISC-V Linux
- MacOS
- Windows
The computer you are currently using is a good platform to start with as well as any common embedded Linux platform like the Raspberry PI.
If you needed an industrial class device, consider something from embeddedTS
like the TS-7553-V2.
The Simple IoT application is a self contained binary with no dependencies. Download the latest release for your platform and run the executable. Once running, you can log into the user interface by opening http://localhost:8118 in a browser. The default login is:
- user:
admin - pass:
admin
Simple IoT self-install (Linux only)
Simple IoT self-installation does the following:
- creates a Systemd service file
- creates a data directory
- starts and enables the service
To install as user, copy the siot binary to some location like
/usr/local/bin and then run:
siot install
To install as root:
sudo siot install
The default ports are used, so if you want something different, modify the
generated siot.service file.
Cloud/Server deployments
When on the public Internet, Simple IoT should be proxied by a web server like Caddy to provide TLS/HTTPS security. Caddy by default obtains free TLS certificates from Let’s Encrypt and ZeroSSL with automatic fallback if one provider fails.
There are Ansible recipes available to deploy Simple IoT, Caddy, InfluxDB, and Grafana that work on most Linux servers.
Video: Setting up a Simple IoT System in the cloud
Yocto Linux
Yocto Linux is a popular edge Linux solution. There is a BitBake recipe for including Simple IoT in Yocto builds.
Networking
By default, Simple IoT runs an embedded NATS server and the SIOT NATS client is
configured to connect to nats://127.0.0.1:4222.
Use Cases
Simple IoT is platform that can be used to build IoT systems where you want to synchronize data between a number of distributed devices to a common central point (typically in the cloud). A common use case is connected devices where users want to remotely monitor and control these devices.
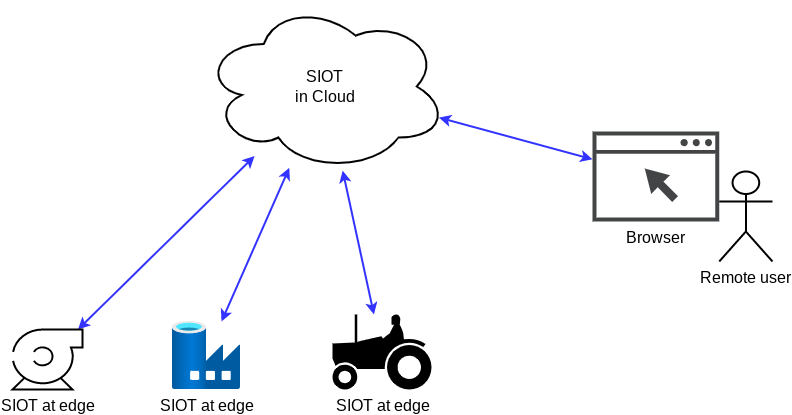
Some examples systems include:
- Irrigation monitoring
- Alarm/building control
- Industrial vehicle monitoring (commercial mowers, agricultural equipment, etc.)
- Factory automation
SIOT is optimized for systems where you run Embedded Linux at the edge and have fairly complex config/state that needs synchronized between the edge and the cloud.
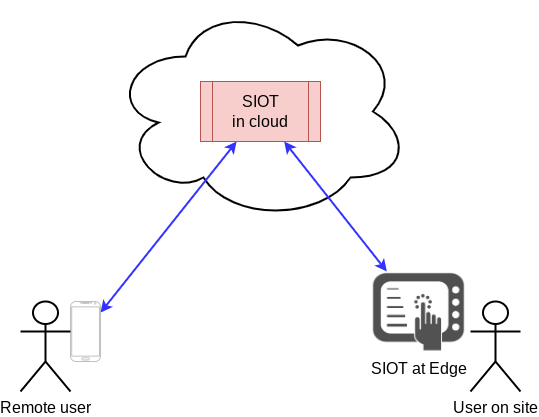
Changes can be made anywhere
Changes to config/state can be made locally or remotely in a SIOT system.
Integration
There are many ways to integrate Simple IoT with other applications.
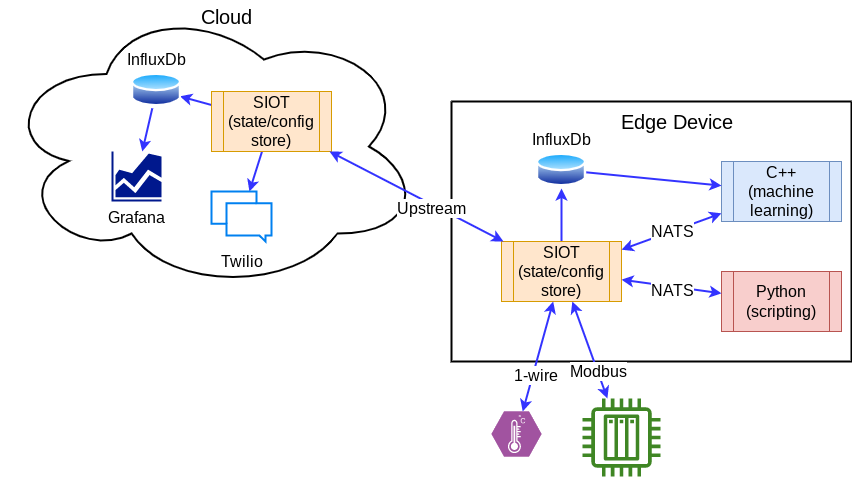
There are cases where some tasks like machine learning are easier to do in languages like C++, then you can connect these applications to SIOT via NATS to access config/state. See the Integration reference guide for more detailed information.
Multiple upstreams
Because we run the same SIOT application everywhere, we can add upstream instances at multiple levels.
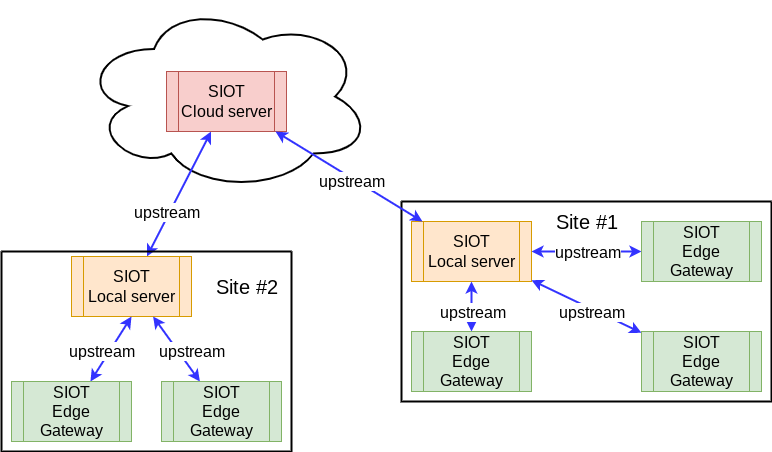
This flexibility allows us to run rules and other logic at any level (cloud, local server, or edge gateway) - wherever it makes sense.
User Interface
Contents
Basic Navigation
After Simple IoT is started, a web application is available on port :8118
(typically http://localhost:8118). After logging in
(default user/pass is admin/admin), you will be presented with a tree of
nodes.
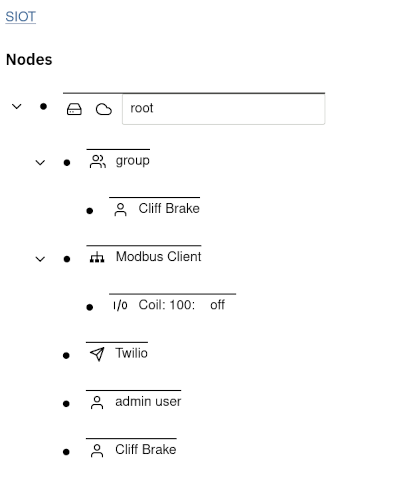
The Node is the base unit of configuration. Each node contains Points which
describe various attributes of a node. When you expand a node, the information
you see is a rendering of the point data in the node.
You can expand/collapse child nodes by clicking on the arrow
![]() to the left of a node.
to the left of a node.
You can expand/edit node details by clicking on the dot
![]() to the left of a node.
to the left of a node.
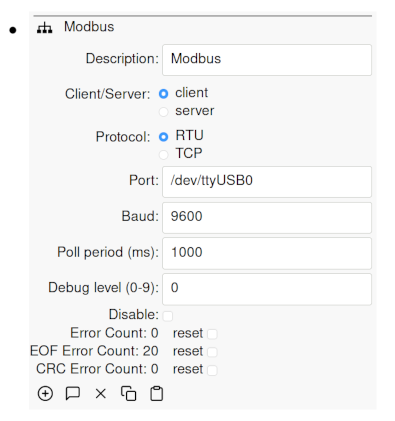
Adding nodes
Child nodes can be added to a node by clicking on the dot to expand the node, then clicking on the plus icon. A list of available nodes to add will then be displayed:
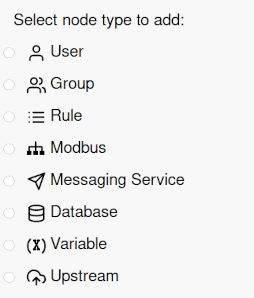
Some nodes are populated automatically if a new device is discovered, or a downstream device starts sending data.
Deleting, Moving, Mirroring, and Duplicating nodes
Simple IoT provides the ability to re-arrange and organize your node structure.
To delete a node, expand it, and then press the delete
![]() icon.
icon.
To move or copy a node, expand it and press the copy
![]() icon. Then expand the destination node and
press the paste
icon. Then expand the destination node and
press the paste ![]() icon. You will then be
presented with the following options:
icon. You will then be
presented with the following options:
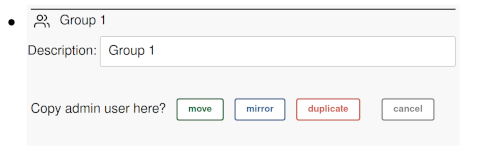
move- moves a node to new locationmirror- is useful if you want a user or device to be a member of multiple groups. If you change a node, all the mirror copies of the node update as well.duplicate- recursively duplicates the copied node plus all its descendants. This is useful for scenarios where you have a device or site configuration (perhaps a complex Modbus setup) that you want to duplicate at a new site.
Raw Node View
If a node is expanded, a raw node button is available that allows you to view the raw type and points for any node in the tree. It is useful at times during development and debugging to be able to view the raw points for a node.
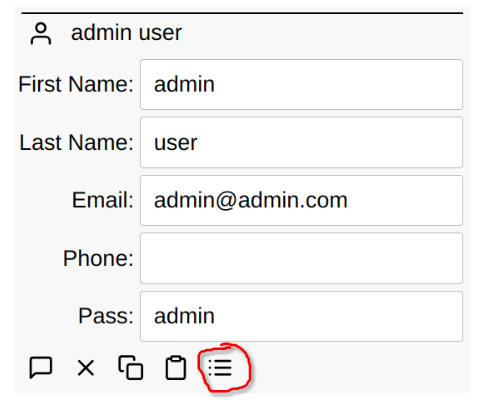
After the raw button is pressed, the type and points are displayed:
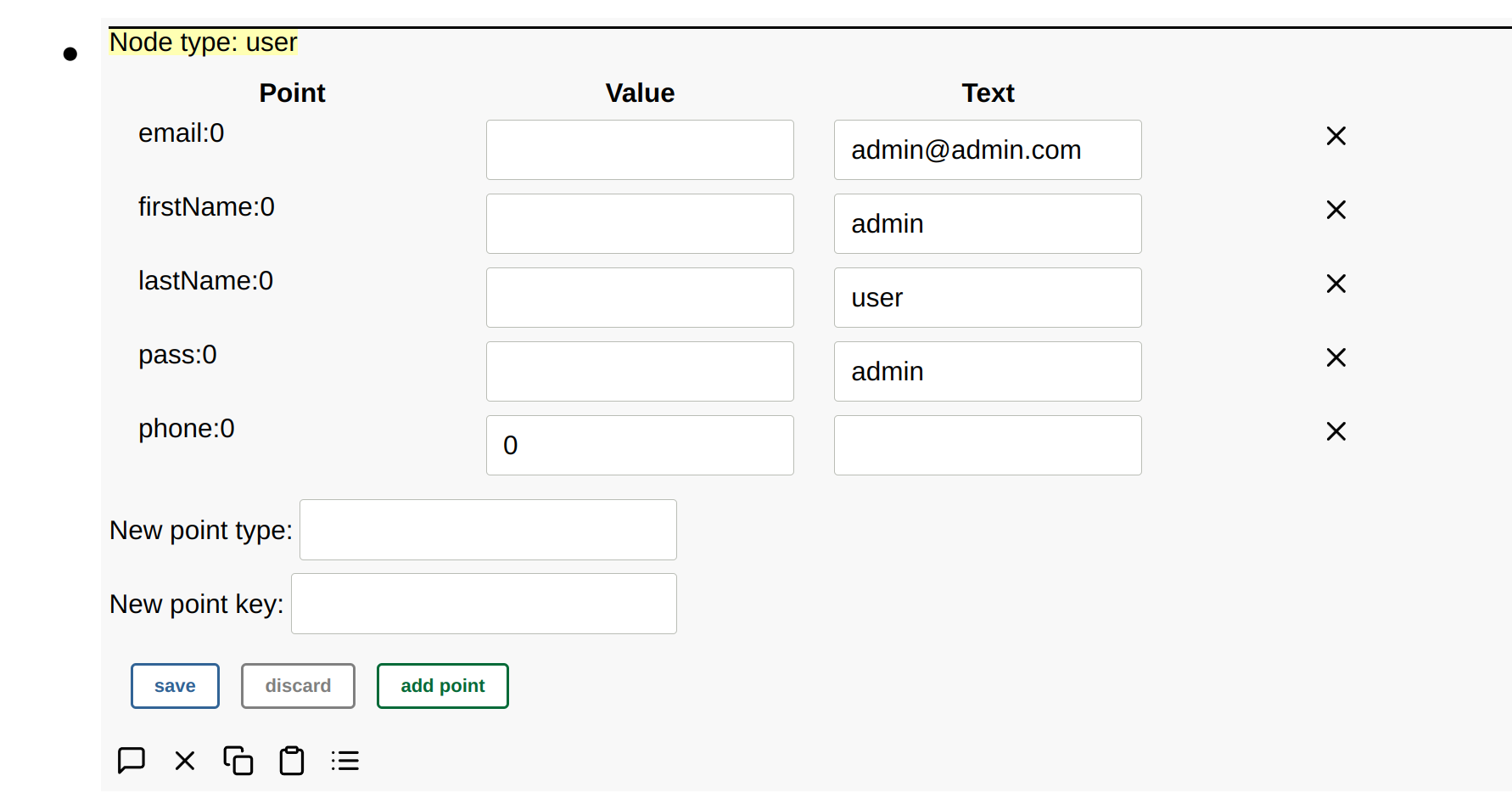
Unknown nodes will also be displayed as raw nodes.
Points can also be edited, added, or removed in raw mode.
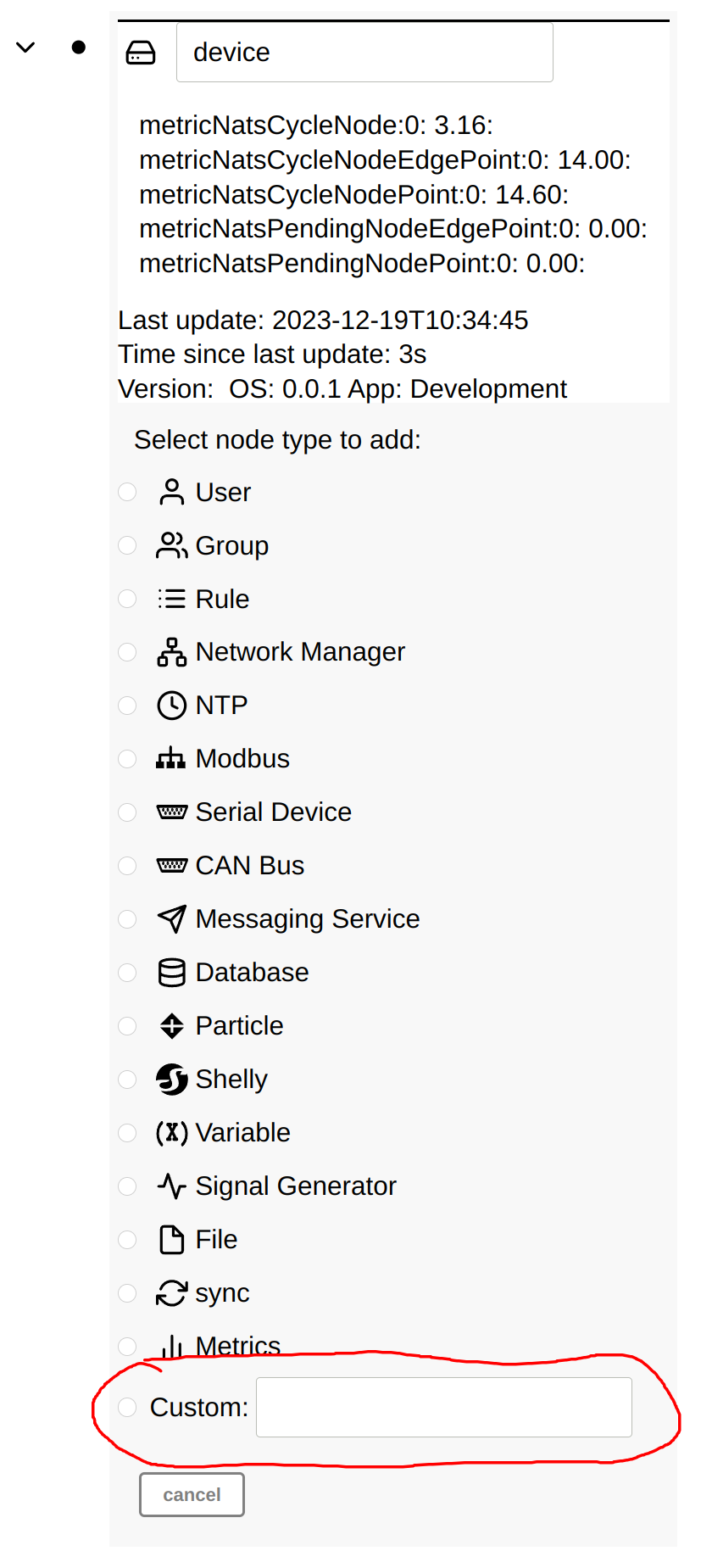
A custom node type can also be added by specifying the node type when adding a node. This can be useful when developing new clients or external clients that run outside of the SImple IoT application.
Graphing and advanced dashboards
If you need graphs and more advanced dashboards, consider coupling Simple IoT with Grafana. Someday we hope to have dashboard capabilities built in.
Custom UIs
See the frontend reference documentation.
Users/Groups
Users and Groups can be configured at any place in the node tree. The way
permissions work is users have access to the parent node and the parent nodes
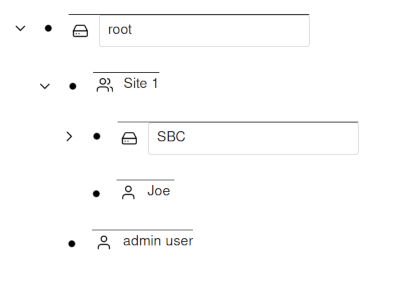
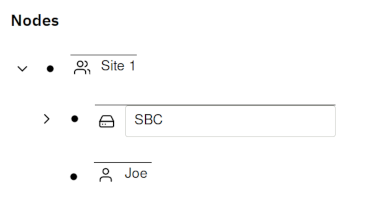
children. In the below example, Joe has access to the SBC device because
both Joe and SBC are members of the Site 1 group. Joe does have access
to the root node.
If Joe logs in, the following view will be presented:
Notifications
Notifications are sent to users when a rule goes from inactive to active and contains a notification action. This notification travels up the node graph. At each parent node, users potentially listen for notifications. If a user is found, then a message is generated. This message likewise travels up the node graph. At each parent node, messaging service nodes potentially listen for messages and then process the message. Each node in Simple IoT that generates information is not concerned with the recipient of the information or how the information is used. This decoupling is the essence of messaging based systems (we use NATS) and is very flexible and powerful. Because nodes can be aliased (mirrored) to different places, this gives us a lot of flexibility in how points are processed. The node tree also gives us a very visual view of how things are connected as well as an easy way to expand or narrow scope based on high in the hierarchy a node is placed.
Example
There is hierarchy of nodes in this example system:
- Company
XYZ- Twilio SMS
Plant A- Joe
- Motor overload Rule
Line #1- Motor Overload
Plant B
The node hierarchy is used to manage scope and permissions. The general rule is
that a node has access to (or applies to) its parent nodes, and all of its
parents dependents. So in this example, Joe has access to everything in Plant
A, and likewise gets any Plant A notifications. The Motor overload rule also
applies to anything in Plant A. This allows us to write one rule that could
apply to multiple lines. The Twilio SMS node processes any messages generated in
Company XYZ including those generated in Plant A, Line #1, Plant B, etc.
and can be considered a company wide resource.
The process for generating an SMS notification to a user is as follows:
Line #1contains aMotor Overloadsensor. When this value changes, a point (blue) gets sent to its parentLine #1and then toPlant A. Although it is not shown below, the point also gets sent to theCompany XYZand root nodes. Points always are rebroadcast on every parent node back to the root.Plant Acontains a rule (Motor Overload) that is then run on the point, which generates a notification (purple) that gets sent back up to its parent (Plant A).Plant Acontains a userJoeso a notification + user generates a message (green), which gets sent back upstream toPlant Aand then toCompany XYZ.Company XYZcontains a messaging service (Twilio SMS), so the message gets processed by this service an SMS message gets sent toJoe.
The Motor Overload sensor node only generates what it senses. The Motor Overload
rule listens for points in Plant A (its parent) and processes those points.
The Joe user node listens for points at the Plant A node (its parent) and
processes any points that are relevant. The Twilio SMS node listens for point
changes at the Company XYZ node and processes those points. Information only
travels upstream (or up the node hierarchy).
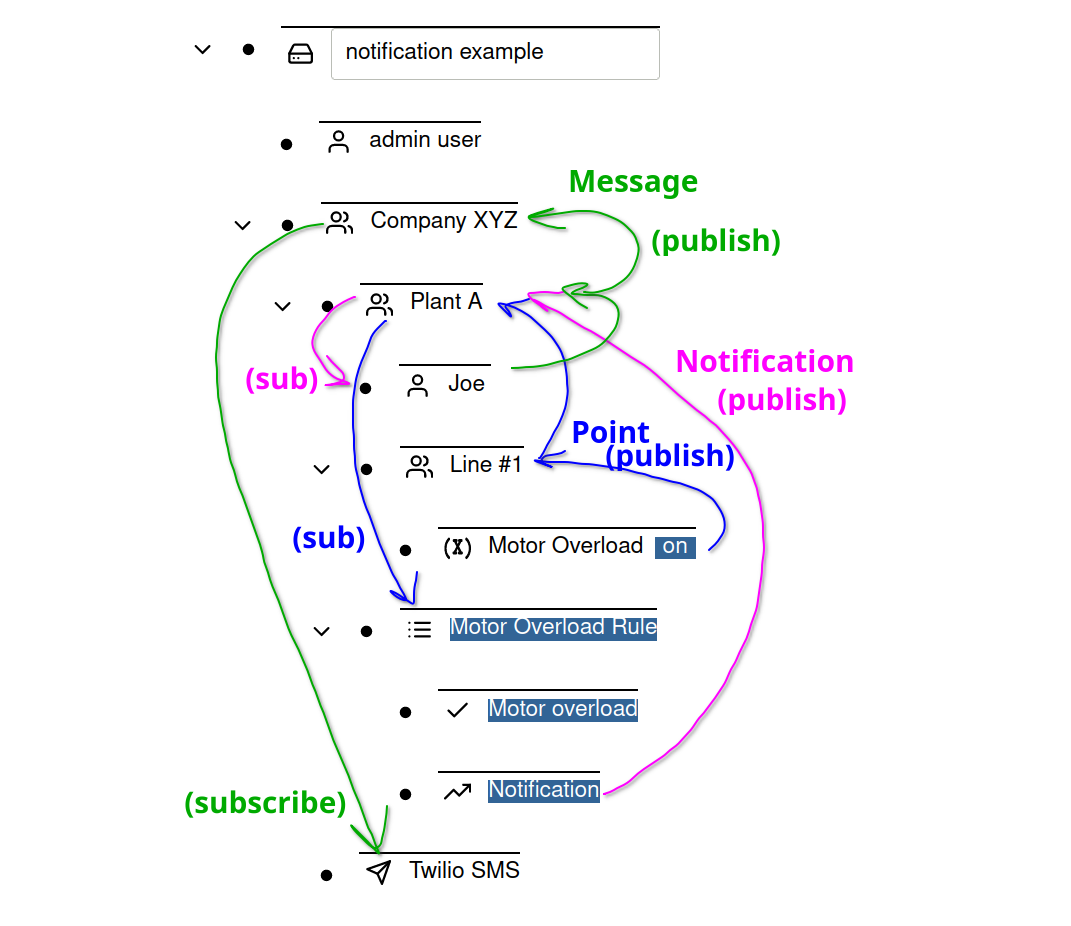
In this example, the admin user does not receive notifications from the Twilio SMS messaging service. The reason is that the Twilio SMS node only listens for messages on its parent node. It does not have visibility into messages sent to the root node. With the node hierarchy, we can easily partition who gets notified. Additional group layers can be added if needed. No explicit binding is required between any of the nodes - the location in the graph manages all that. The higher up you go, the more visibility and access a node has.
Clients
Simple IoT is a framework that allows for clients to be added to manage IO, run rules, process data, etc. See documentation for individual clients. If you would like to develop a custom client, see the client reference documentation.
CAN Bus Client
The CAN client allows loading a standard CAN database file, receiving CAN data, and translating the CAN data into points via the database.
Usage
The CAN client can be used as part of the SimpleIoT library or through the web UI. The first step in either case is to create a CAN database in .kbc format.
Create the CAN Database
Create a file in the folder with the Go code named “test.kcd” containing the following:
<NetworkDefinition xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://kayak.2codeornot2code.org/1.0" xsi:schemaLocation="Definition.xsd">
<Document name="Some Document Name">some text</Document>
<Bus name="sampledatabase">
<Message id="0x123" name="HelloWorld" length="8">
<Notes></Notes>
<Signal name="Hello" offset="0" length="8"/>
<Signal name="World" offset="8" length="8"/>
</Message>
<Message id="0x12345678" name="Food" length="8" format="extended">
<Notes></Notes>
<Signal name="State" offset="0" length="32"/>
<Signal name="Type" offset="32" length="32"/>
</Message>
</Bus>
</NetworkDefinition>
You can create any CAN database you want by crafting it in Kvaser’s free DBC
editor and then using the canmatrix tool to convert it to KCD format. Note
that canmatrix does not support all features of the DBC and KCD formats.
Next, setup the virtual SocketCan interface.
Setup Virtual CAN Interface
Run this in the command line. Reference
sudo modprobe vcan
sudo ip link add dev vcan0 type vcan
sudo ip link set up vcan0
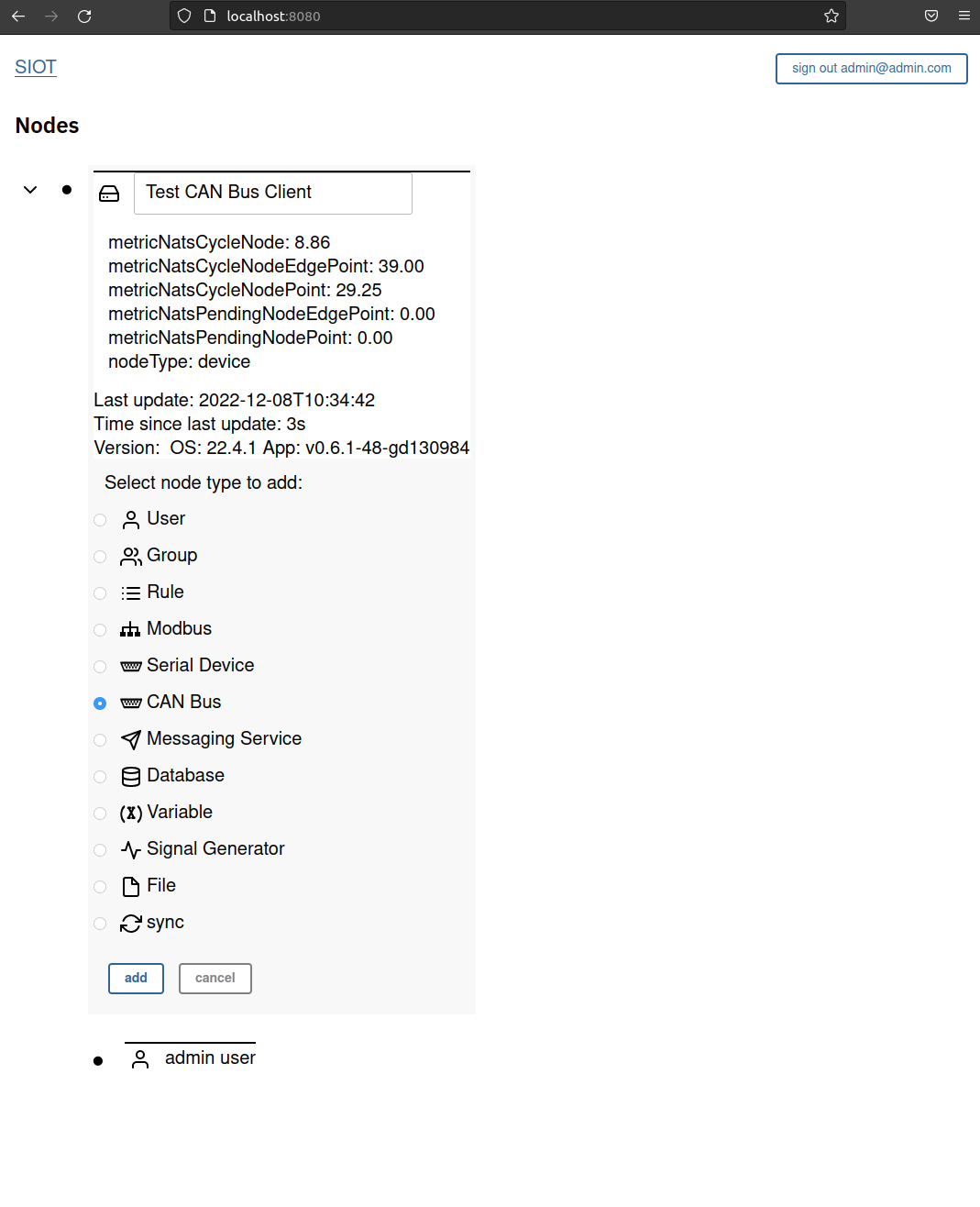
Option #1 - Use In Web UI
Follow the instructions to install SimpleIoT, run it, and navigate to the web UI.
Expand the root node and click the + symbol to add a sub node. Select “CAN Bus” and click “add”.
Configure the CAN Bus node with a File subnode and upload the .kcd
file you created.
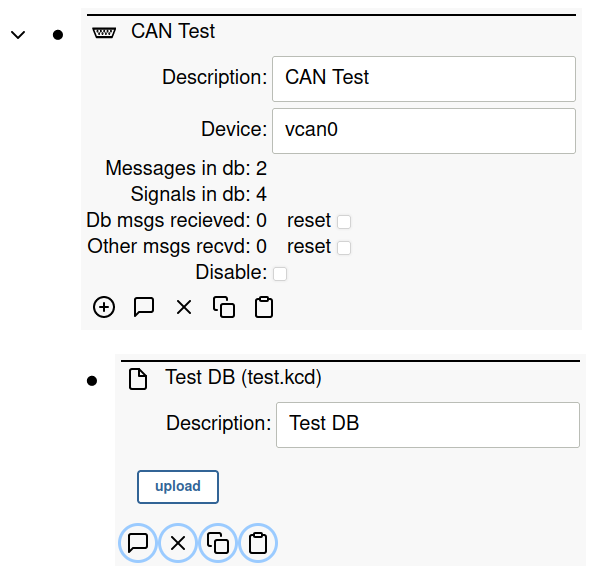
Once the file has been uploaded, you should see the following stats in the CAN bus node:
Messages in db: 2 Signals in db: 4
Test with Messages
In a separate terminal:
cansend vcan0 123#R{8}
cansend vcan0 12345678#DEADBEEF
Ensure that there are no errors logged in the terminal by the application.
In the Web UI you should see the "Db msgs received" field increase to 2.
Option #2 - Use As Library
Copy this code to a Go file on your Linux machine in a folder by itself.
package main
import (
"log"
"github.com/nats-io/nats.go"
"github.com/simpleiot/simpleiot/client"
"github.com/simpleiot/simpleiot/data"
"github.com/simpleiot/simpleiot/server"
)
// exNode is decoded data from the client node
type exNode struct {
ID string `node:"id"`
Parent string `node:"parent"`
Description string `point:"description"`
Port int `point:"port"`
Role string `edgepoint:"role"`
}
// exNodeClient contains the logic for this client
type exNodeClient struct {
nc *nats.Conn
config client.SerialDev
stop chan struct{}
stopped chan struct{}
newPoints chan client.NewPoints
newEdgePoints chan client.NewPoints
chGetConfig chan chan client.SerialDev
}
// newExNodeClient is passed to the NewManager() function call -- when
// a new node is detected, the Manager will call this function to construct
// a new client.
func newExNodeClient(nc *nats.Conn, config client.SerialDev) client.Client {
return &exNodeClient{
nc: nc,
config: config,
stop: make(chan struct{}),
newPoints: make(chan client.NewPoints),
newEdgePoints: make(chan client.NewPoints),
}
}
// Start runs the main logic for this client and blocks until stopped
func (tnc *exNodeClient) Run() error {
for {
select {
case <-tnc.stop:
close(tnc.stopped)
return nil
case pts := <-tnc.newPoints:
err := data.MergePoints(pts.ID, pts.Points, &tnc.config)
if err != nil {
log.Println("error merging new points:", err)
}
log.Printf("New config: %+v\n", tnc.config)
case pts := <-tnc.newEdgePoints:
err := data.MergeEdgePoints(pts.ID, pts.Parent, pts.Points, &tnc.config)
if err != nil {
log.Println("error merging new points:", err)
}
case ch := <-tnc.chGetConfig:
ch <- tnc.config
}
}
}
// Stop sends a signal to the Run function to exit
func (tnc *exNodeClient) Stop(err error) {
close(tnc.stop)
}
// Points is called by the Manager when new points for this
// node are received.
func (tnc *exNodeClient) Points(id string, points []data.Point) {
tnc.newPoints <- client.NewPoints{id, "", points}
}
// EdgePoints is called by the Manager when new edge points for this
// node are received.
func (tnc *exNodeClient) EdgePoints(id, parent string, points []data.Point) {
tnc.newEdgePoints <- client.NewPoints{id, parent, points}
}
func main() {
nc, root, stop, err := server.TestServer()
if err != nil {
log.Println("Error starting test server:", err)
}
defer stop()
canBusTest := client.CanBus{
ID: "ID-canBus",
Parent: root.ID,
Description: "vcan0",
Device: "vcan0",
}
err = client.SendNodeType(nc, canBusTest, "test")
if err != nil {
log.Println("Error sending CAN node:", err)
}
// Create a new manager for nodes of type "testNode". The manager looks for new nodes under the
// root and if it finds any, it instantiates a new client, and sends point updates to it
m := client.NewManager(nc, newExNodeClient)
m.Start()
// Now any updates to the node will trigger Points/EdgePoints callbacks in the above client
}
Run the following commands:
go mod init example.com/mgo run <file>.go- Run the
go getcommands suggested bygo run go mod tidygo run <file>.go
Run it!
go run <file.go>
Follow instructions from the “Test with Messages” section above.
Future Work
- Scale and translate messages based on scale and offset parameters in database
- Auto connect to CAN bus in case it is brought up after SIOT client is started
- Attempt to bring up CAN bus within client, handle case where it is already up
- Support multiple CAN database files per node (be selective in which internal db is updated when a name or data point is received in the client)
- Support sending messages (concept of nodes and send/receive pulled from databases??)
- Support
.dbcfile format in addition to.kcd - Add the concept of a device to the CAN message points
File
The file node can be used to store files that are then used by other nodes/clients. Some examples include the CAN and Serial clients.
The default max payload of NATS is 1MB, so that is currently the file size limit, but NATS can be configured for a payload size up to 64MB. 8MB is recommended.
See the Frontend documentation for more information how the file UI is implemented.
If the Binary option is selected, the data is base64 encoded before it is
transmitted and stored.
Database Client
The main SIOT store is SQLite. SIOT supports additional database clients for purposes such as storing time-series data.
InfluxDB 2.x
Point data can be stored in an InfluxDB 2.0 Database by adding a Database node:
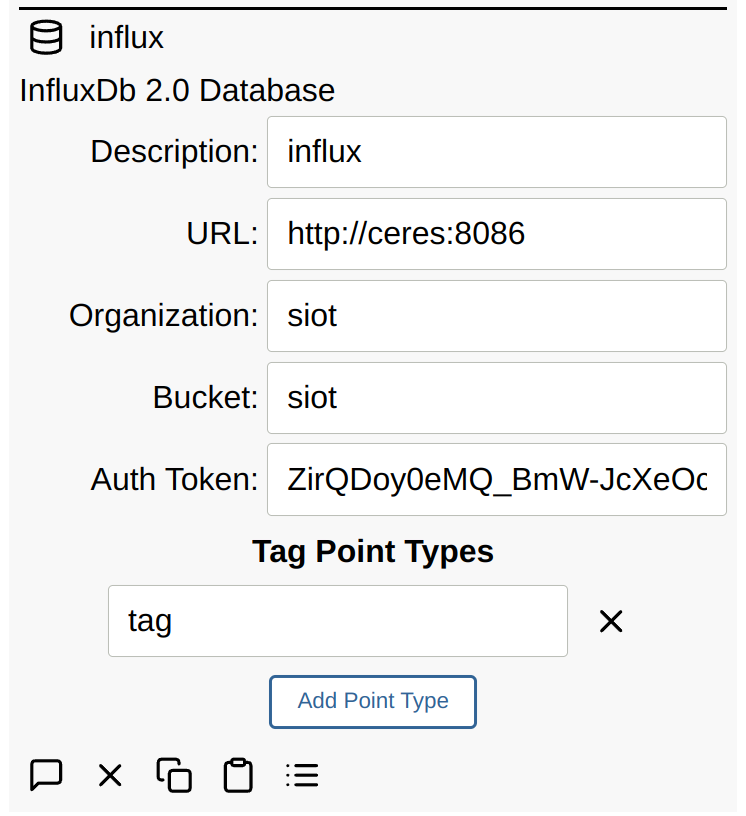
The following InfluxDB tags are added to every point:
node.id(typically an UUID)node.type(extracted from the type field in the edge data structure)node.description(generated from thedescriptionpoint from the node)
Custom InfluxDB Tags
Additional tag tag points can be specified. The DB client will query and cache
node points of these types for any point flowing through the system and then
InfluxDB tags in the format: node.<point type>.<point key>. In the below
example, we added a machine tag to the signal generator node generating the
data.
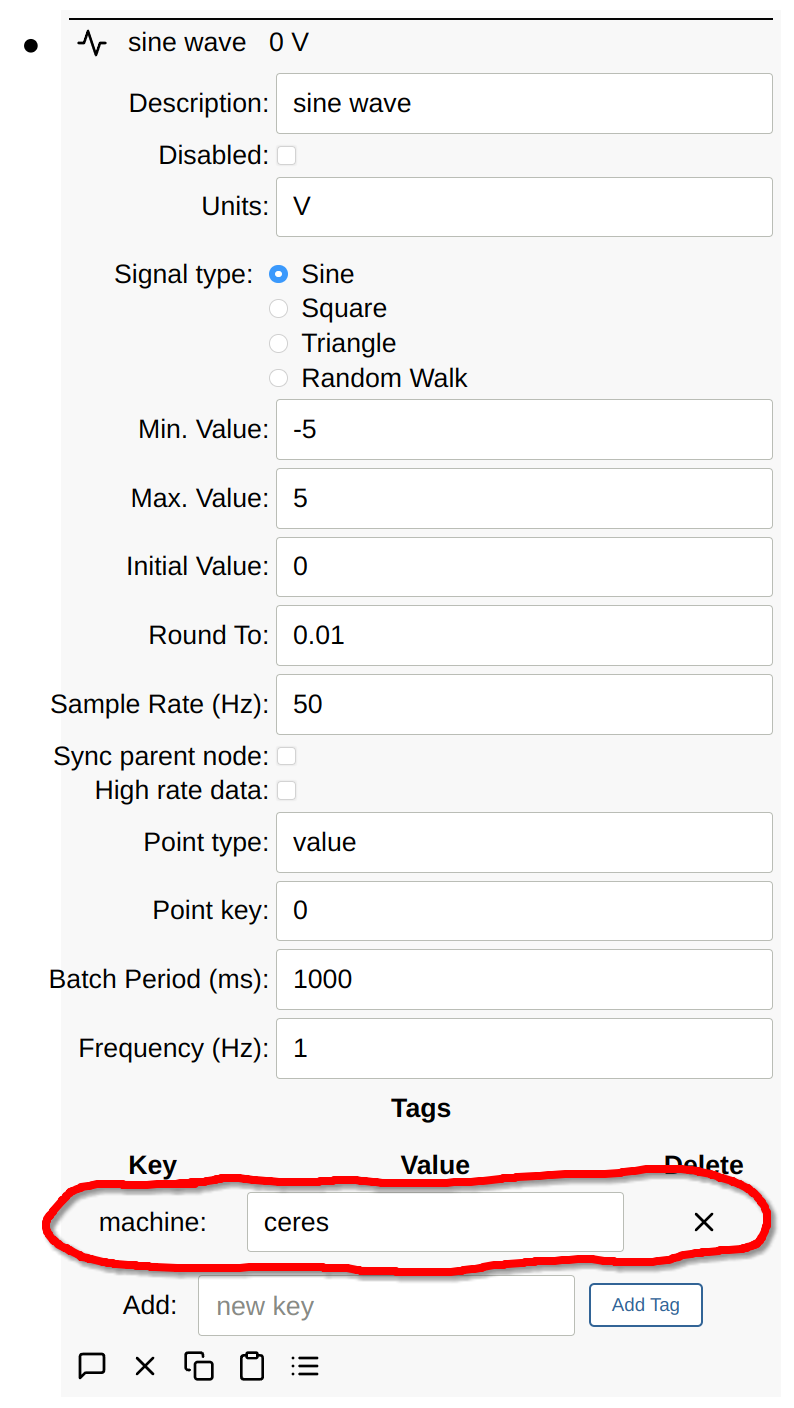
When the tag field is specified in the database node, this machine tag is
now added to the Influx tags for every sample.
valueandtypeand fields from the pointnode.descriptionandnode.typeare automatically addednode.tag.machinegot added because thetagpoint was added to the list of node points that get added as tags.
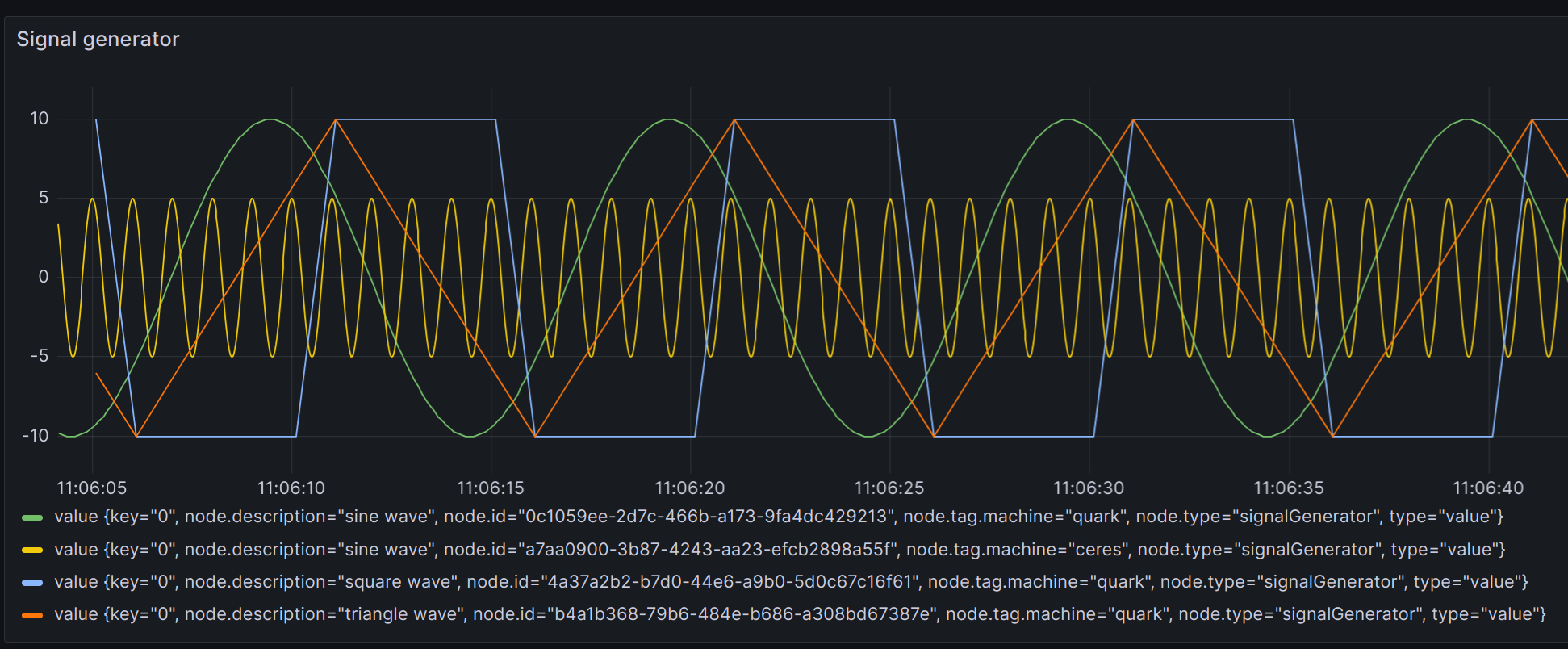
See the Graphing documentation for information on how to automatically map tags to graph labels.
InfluxDB indexes tags, so generally there is not a huge cost to adding tags to samples as the long string is only stored once.
Victoria Metrics
Victoria Metrics supports the InfluxDB version 2 line protocol; therefore, it can be used for numerical data. Victoria Metrics does not support storing strings.
Modbus
Modbus is popular data communications protocol used for connecting industrial devices. The specification is open and available at the Modbus website. See also this Modbus Overview.
Simple IoT can function as both a Modbus client or server and supports both RTU and TCP transports. Modbus client/server is used as follows:
- Client: typically a PLC or Gateway - the device reading sensors and initiating Modbus transactions. This is the mode to use if you want to read sensor data and then process it or send to an upstream instance.
- Server: typically a sensor, actuator, or other device responding to Modbus requests. Functioning as a server allows SIOT to simulate Modbus devices or to provide data to another client device like a PLC.
Modbus is a prompt response protocol. With Modbus RTU (RS485), you can only have one client (gateway) on the bus and multiple servers (sensors). With Modbus TCP, you can have multiple clients and servers.
Modbus is configured by adding a Modbus node to the root node, and then adding IO nodes to the Modbus node.
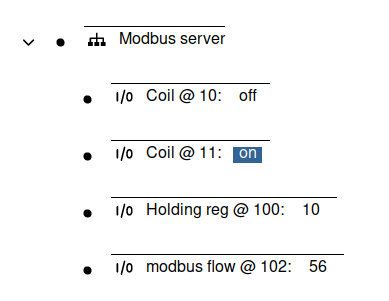
The Response timeout parameter determines how long the Modbus client will wait
for a response from a device. The default is 100ms, which is adequate for most
devices, but it can be increased if you are communicating with a slow device.
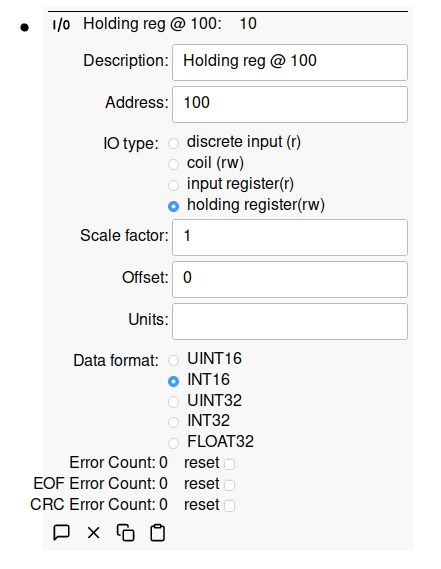
Modbus IOs can be configured to support most common IO types and data formats:
Videos
Simple IoT Integration with PLC Using Modbus
Simple IoT upstream synchronization support
Simple IoT Modbus Demo
1-Wire
1-Wire is a device communication bus that provides low-speed data over a single conductor. It is also possible to power some devices over the data signal as well, but often a third wire is run for power.
Simple IoT supports 1-wire buses controlled by the
1-wire (w1) subsystem
in the Linux kernel. Simple IoT will automatically create nodes for 1-wire buses
and devices it discovers.

Bus Controllers
Raspberry PI GPIO
There are a number of bus controllers available but one of the simplest is a
GPIO on a Raspberry PI. To enable, add the following to the /boot/config.txt
file:
dtoverlay=w1-gpio
This enables a 1-wire bus on GPIO 4.
To add a bus to a different pin:
dtoverlay=w1-gpio,gpiopin=x
A 4.7kΩ pull-up resistor is needed between the 1-wire signal and 3.3V. This can be wired to a 0.1 inch connector as shown in the following schematic:
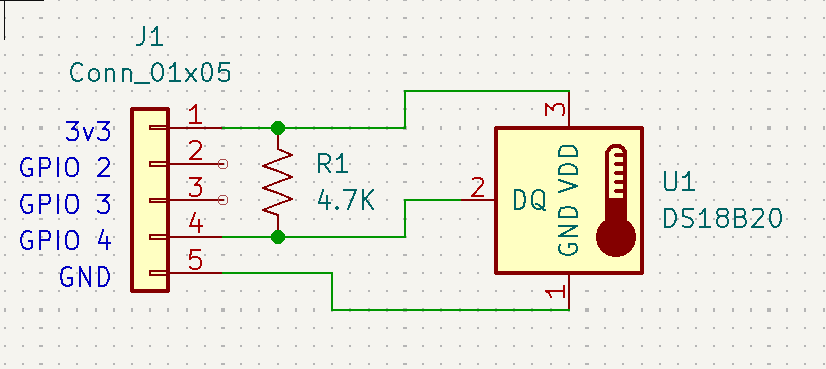
See this page for more information.
1-Wire devices
DS18B20 Temperature sensors
Simple IoT currently supports 1-wire temperature sensors such as the DS18B20.
This is a very popular and practical digital temperature sensor. Each sensor has
a unique address so you can address a number of them using a single 1-wire port.
These devices are readily available at low cost from a number of places
including eBay - search for DS18B20, and look for an image like the below:

Messaging Services
SIOT can support multiple messaging services.
Twilio SMS Messaging
Simple IoT supports sending SMS messages using Twilio’s SMS service. Add a Messaging Service node and then configure.
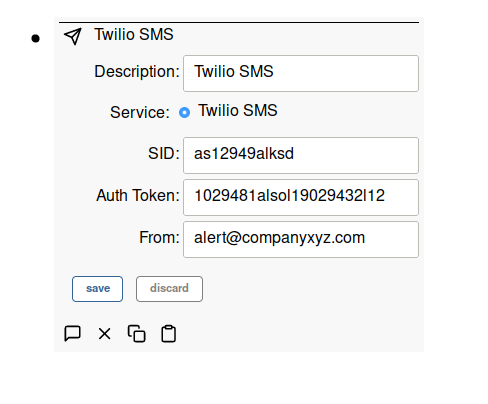
Email Messaging
will be added soon …
MCU Devices
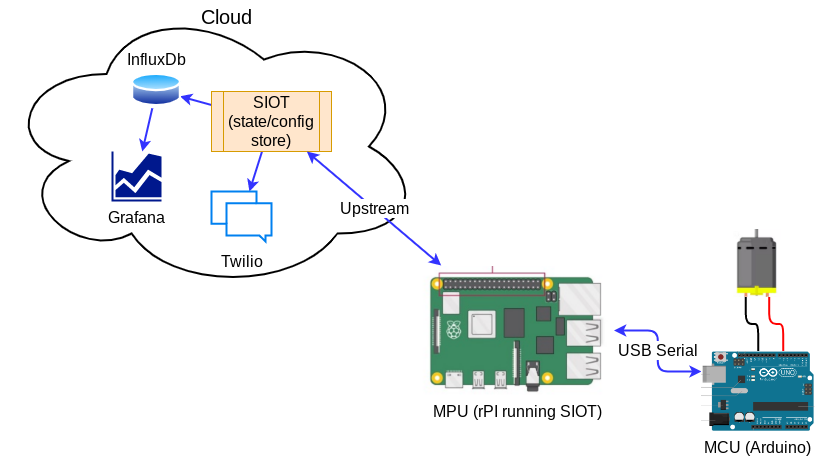
Microcontroller (MCU) devices can be connected to Simple IoT systems via various serial transports (RS232, RS485, CAN, and USB Serial). The Arduino platform is one example of an MCU platform that is easy to use and program. Simple IoT provides a serial interface module that can be used to interface with these systems. The combination of a laptop or a Raspberry PI makes a useful lab device for monitoring analog and digital signals. Data can be logged to InfluxDB and viewed in the InfluxDB Web UI or Grafana. This concept can be scaled into products where you might have a Linux MPU handling data/connectivity and a MCU doing real-time control.
See the Serial reference documentation for more technical details on this client.
File Download
Files (or larger chunks of data) can be downloaded to the MCU by adding a File node to the serial node. Any child File node will then show up as a download option.
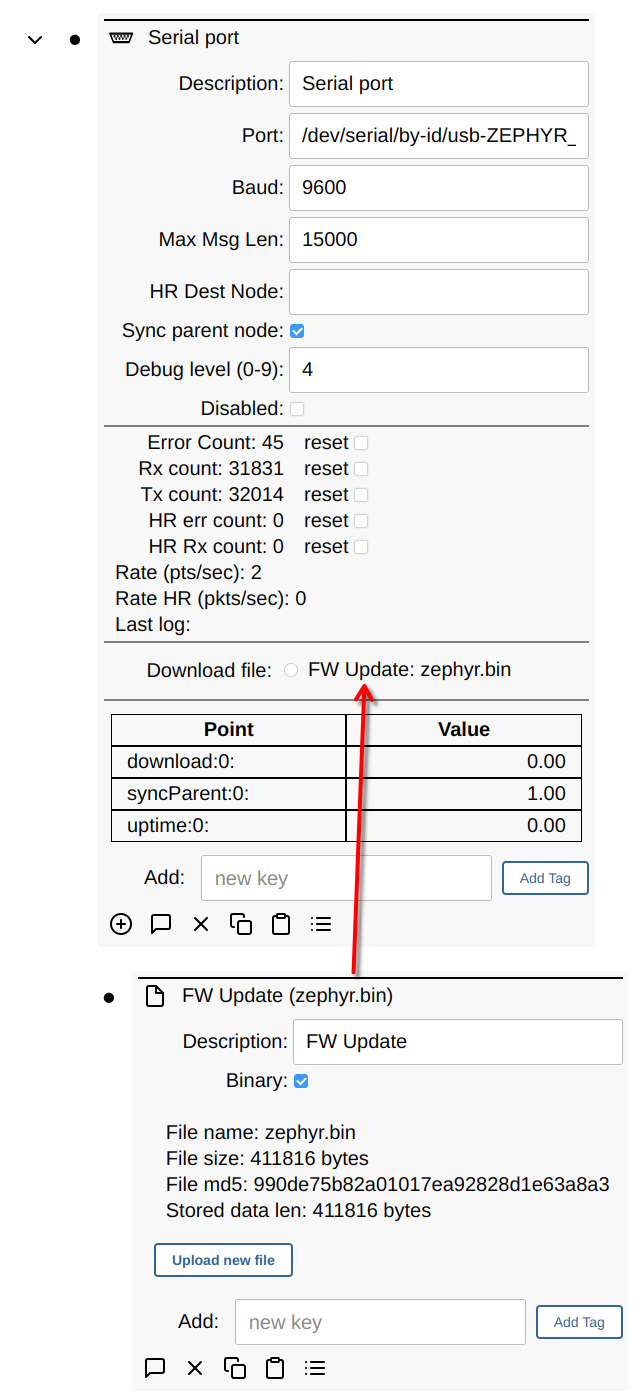
Debug Levels
You can set the following debug levels to log information.
- 0: no debug information
- 1: log ASCII strings (must be COBS wrapped) (typically used for debugging code on the MCU)
- 4: log points received or sent to the MCU
- 8: log cobs decoded data (must be COBS wrapped)
- 9: log raw serial data received (pre-COBS)
Zephyr Examples
The zephyr-siot repository contains examples of MCU firmware that can interface with Simple IoT over serial, USB, and Network connections. This is a work in progress and is not complete.
Arduino Examples (no longer maintained)
Several Arduino examples are available that can be used to demonstrate this functionality.
Metrics
An important part of maintaining healthy systems is to monitor metrics for the application and system. SIOT can collect metrics for:
- the system
- the SIOT application
- any named processes
For the named process, if there are multiple processes of the same name, then we add values for all processes found.
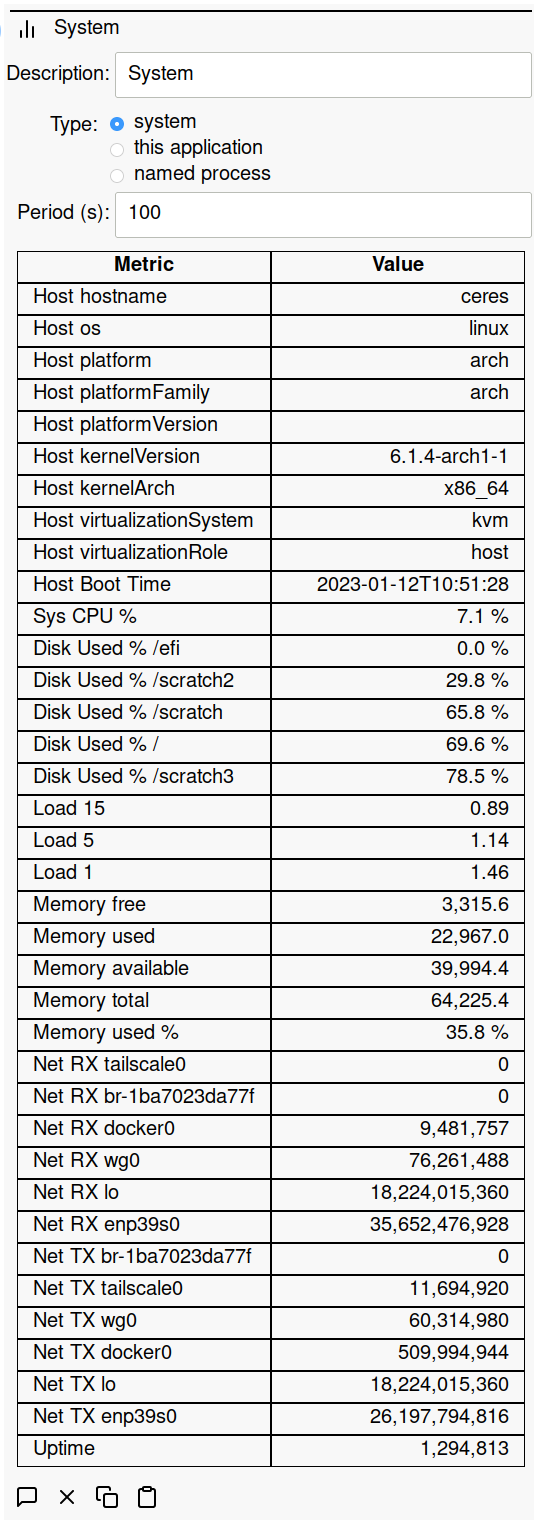
System Metrics
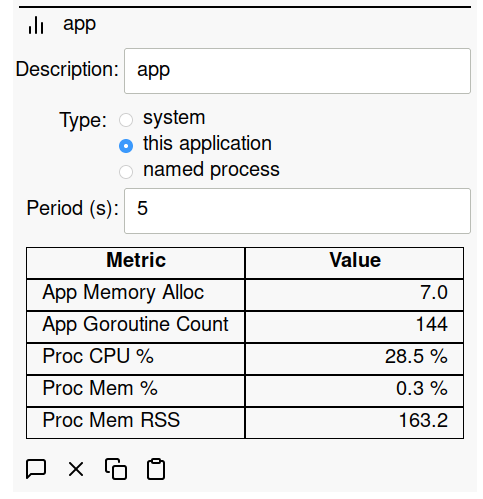
SIOT Application Metrics
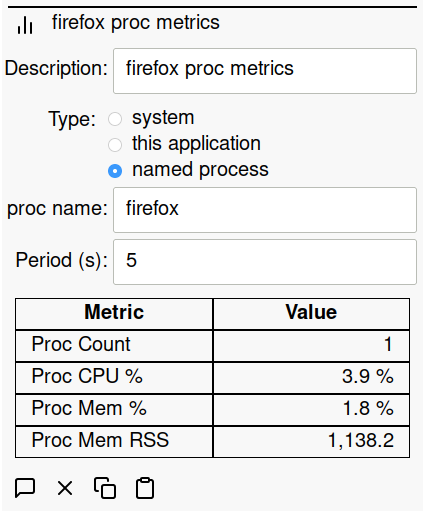
Named Process Metrics
Particle.io
SIOT provides a client for pulling data from Particle.io. Particle provide modules to quickly implement cellular connected MCU based IoT systems. They take care of managing the device (cellular connection, firmware deployments, etc.), and you only need to write the application.
The Particle cloud event API is used to obtain the data. A connection is made from the SIOT instance to the Particle Cloud and then data is sent back to SIOT using Server Sent Events (SSE). The advantage of this mechanism is that complex webhooks are not needed on the SIOT side, which requires additional firewall/web server configuration.
A Particle API key is needed which can be generated using the particle token
CLI command.
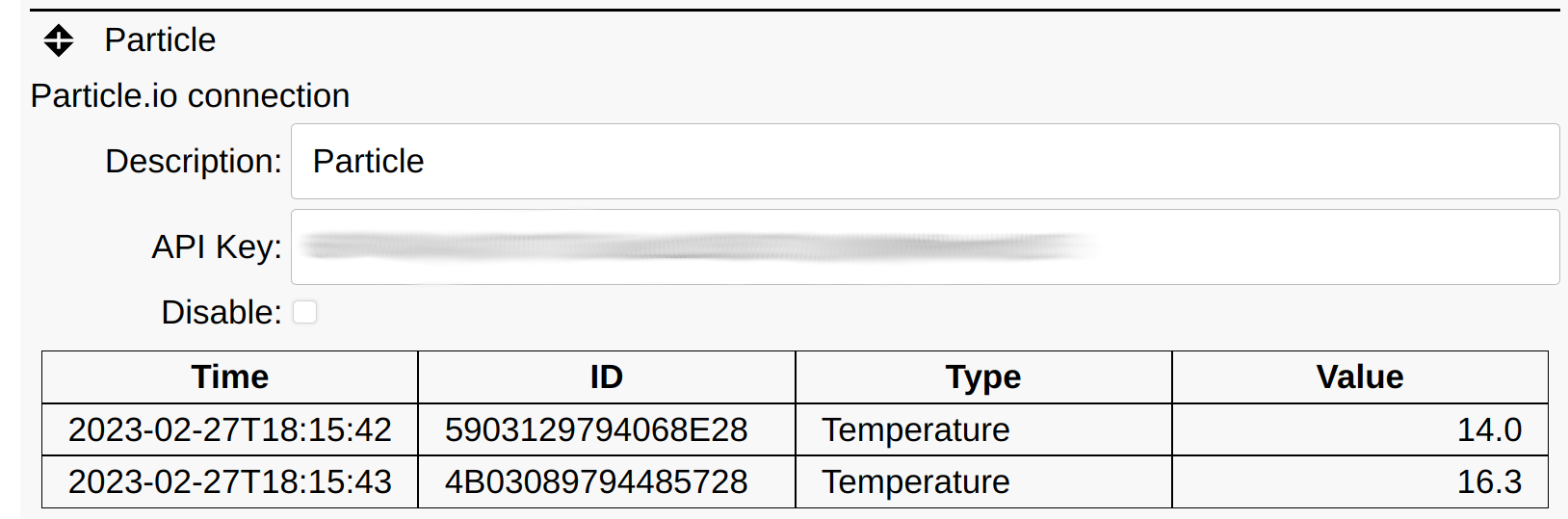
The above example shows data provided by the Particle based Simple IoT Particle Gateway and 1-wire temperature sensors, and SIOT firmware.
Data is published to Particle in the following format:
[
{
"id": "4B03089794485728",
"type": "temp",
"value": 15.25
}
]
The SIOT Particle client populates the point key field with the 1-wire device
ID.


Rules
Contents
The Simple IoT application has the ability to run rules - see the video below for a demo:
Rules are composed of one or more conditions and actions. All conditions must be true for the rule to be active.
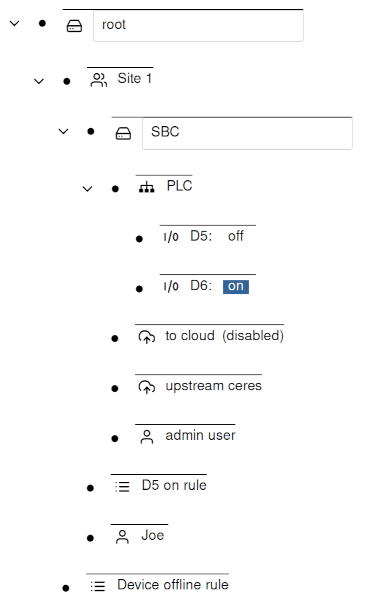
Node point changes cause rules of any parent node in the tree to be run. This allows general rules to be written higher in the tree that are common for all device nodes (for instance device offline).
In the below configuration, a change in the SBC propagates up the node tree,
thus both the D5 on rule or the Device offline rule are eligible to be run.
Node linking
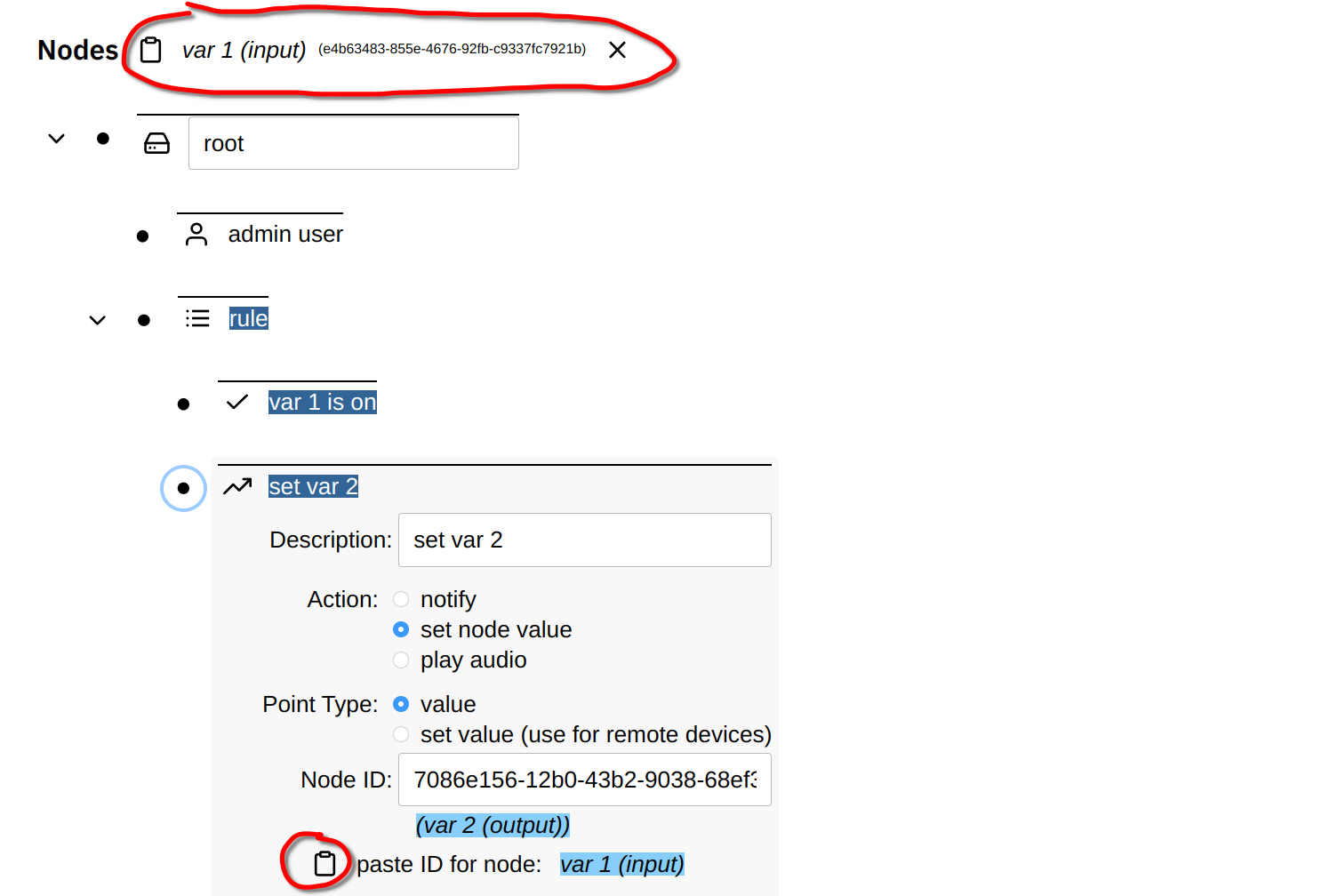
Both conditions and actions can be linked to a node ID. If you copy a node, its ID is stored in a virtual clipboard and displayed at the top of the screen. You can then paste this node ID into the Node ID field in a condition or action.
Conditions
Each condition may optionally specify a minimum active duration before the condition is considered met. This allows timing to be encoded in the rules.
Node state
A point value condition looks at the point value of a node to determine if a condition is met. Qualifiers that filter points the condition is interested in can set including:
- Node ID (if left blank, any node that is a descendant of the rule parent)
- Point type (“value” is probably the most common type)
- Point Key (used to index into point arrays and objects)
If the provided qualification is met, then the condition may check the point value/text fields for a number of conditions including:
- number:
>,<,=,!= - text:
=,!=,contains - boolean:
on,off
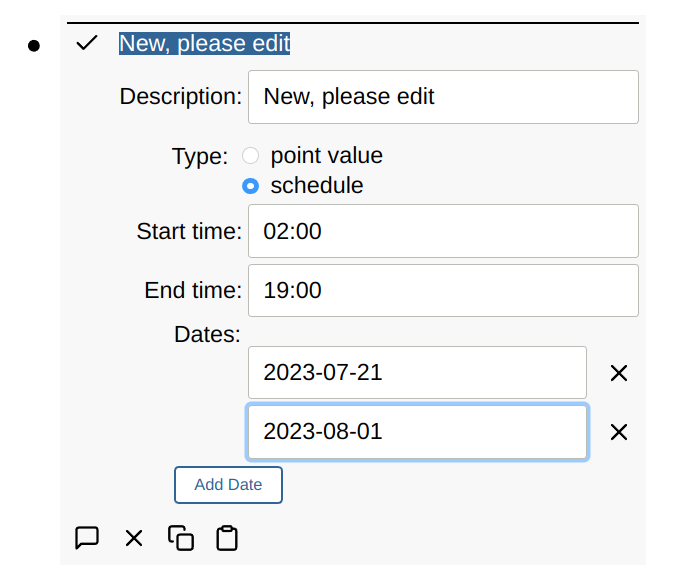
Schedule
Rule conditions can be driven by a schedule that is composed of:
- start/stop time
- weekdays
- dates
If no weekdays are selected, then all weekdays are included.
When the dates are used, then weekdays are disabled.
Conversely, when a weekday is enabled, dates are disabled.
As a time range can span two days, the start time is used to qualify weekdays and dates.
See also a video demo:
Actions
Every action has an optional repeat interval. This allows rate limiting of actions like notifications.
Notifications
Notifications are the simplest rule action and are sent out when:
- All conditions are met
- Time since last notification is greater than the notify action repeat interval.
Every time a notification is sent out by a rule, a point is created/updated in the rule with the following fields:
id: node of point that triggered the ruletype: “lastNotificationSent”time: time the notification was sent
Before sending a notification we scan the points of the rule looking for when the last notification was sent to decide if its time to send it.
Set node point
Rules can also set points in other nodes. For simplicity, the node ID must be currently specified along with point parameters and a number/bool/text value.
Typically a rule action is only used to set one value. In the case of on/off actions, one rule is used to turn a value on, and another rule is used to turn the same value off. This allows for hysteresis and more complex logic than in one rule handled both the on and off states. This also allows the rules logic to be stateful. If you don’t need hysteresis or complex state, the rule “inactive action” can be used, which allows the rule to take action when it goes both active and inactive.
Disable Rule/Condition/Action
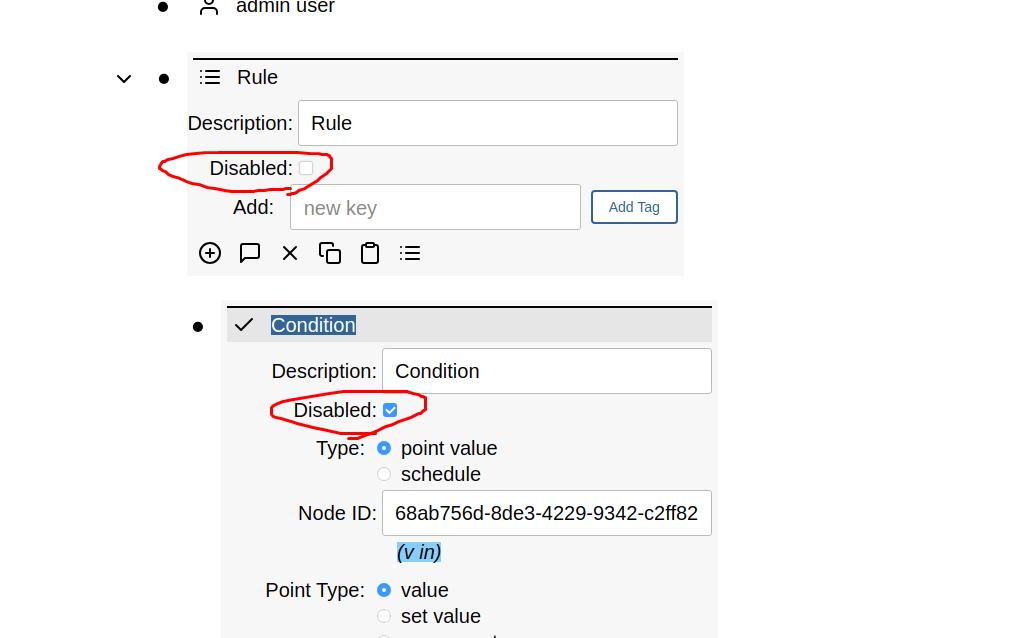
Disable Rule
A rule can be disabled. If the rule is disabled while active, then the rule inactive actions are run so that things get cleaned up if necessary and the actions are not left active.
Disable Condition
If there are no conditions, or all conditions are disabled, the rule is inactive. Otherwise, disabled conditions are simply ignored. For example, if there is a disabled condition and a non-disabled active condition, the rule is active.
Disable Action
A disabled action is not run.
Shelly IoT
Shelly sells a number of reasonably priced open IoT devices for home automation and industrial control. Most support Wi-Fi network connections and some of the Industrial line also supports Ethernet. The API is open and the devices support a number of communication protocols including HTTP, MQTT, CoAP, etc. They also support mDNS so they can be discovered on the network.
Simple IoT provides the following support:
- Automatic discovery of all Shelly devices on the network using mDNS
- Support for the following devices:
1pm(not tested)Bulb Duo(on/off only)Plus 1Plus 1PM(not tested)Plus 2PMPlus Plug(only US variant tested)- Measurements such as Current, Power, Temp, Voltage are collected.
Plus i4
- Currently status is polled via HTTP every 2 seconds
Setup
- Configure the Shelly devices to connect to your Wi-Fi network. There are
several options:
- Use the Shelly phone app
- A new device will start up in access point mode. Attach a computer or phone to this AP, open http://192.168.33.1 (default address of a reset device), and then configure the Wi-Fi credentials using the built-in Web UI.
- Add the Shelly client in SIOT
- The Shelly client will then periodically scan for new devices and add them as child nodes.
Example
Plug Example
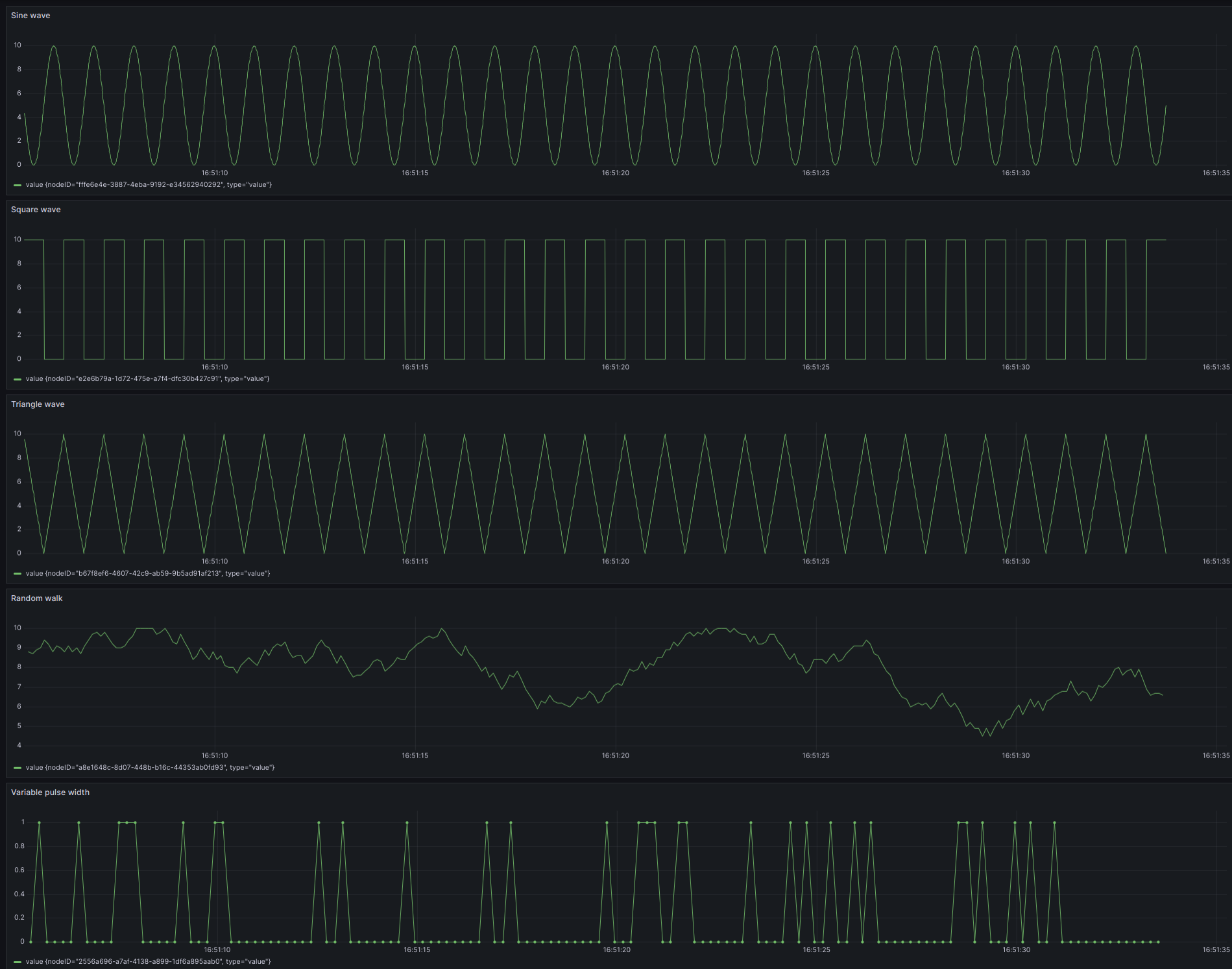
Signal Generator Client
The signal generator can be used to generate various signals including:
- Sine wave
- Square wave
- Triangle wave
- Random walk
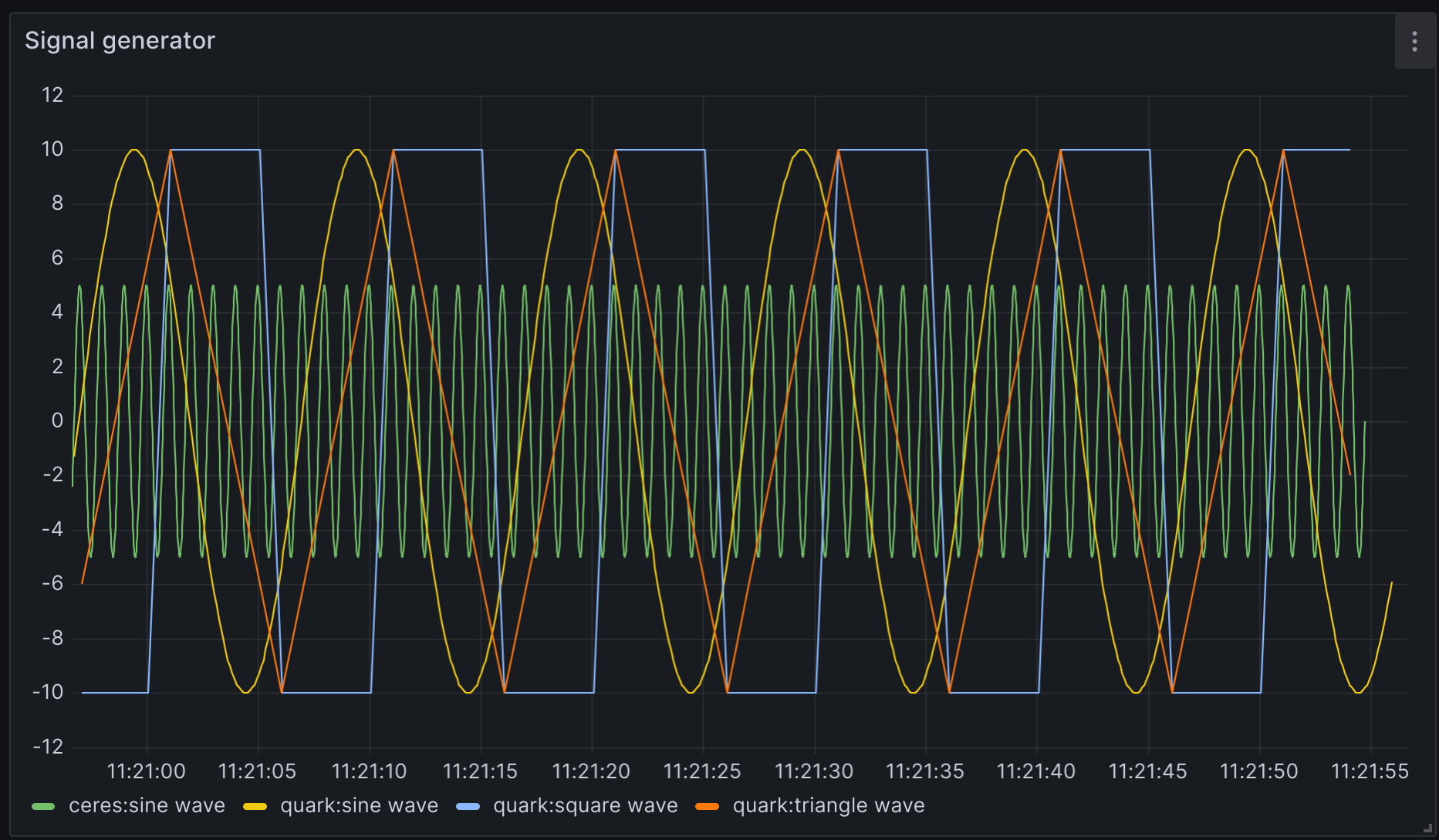
Below is a screen-shot of the generated data displayed in Grafana.
Configuration
The signal generated can be configured with the following parameters:
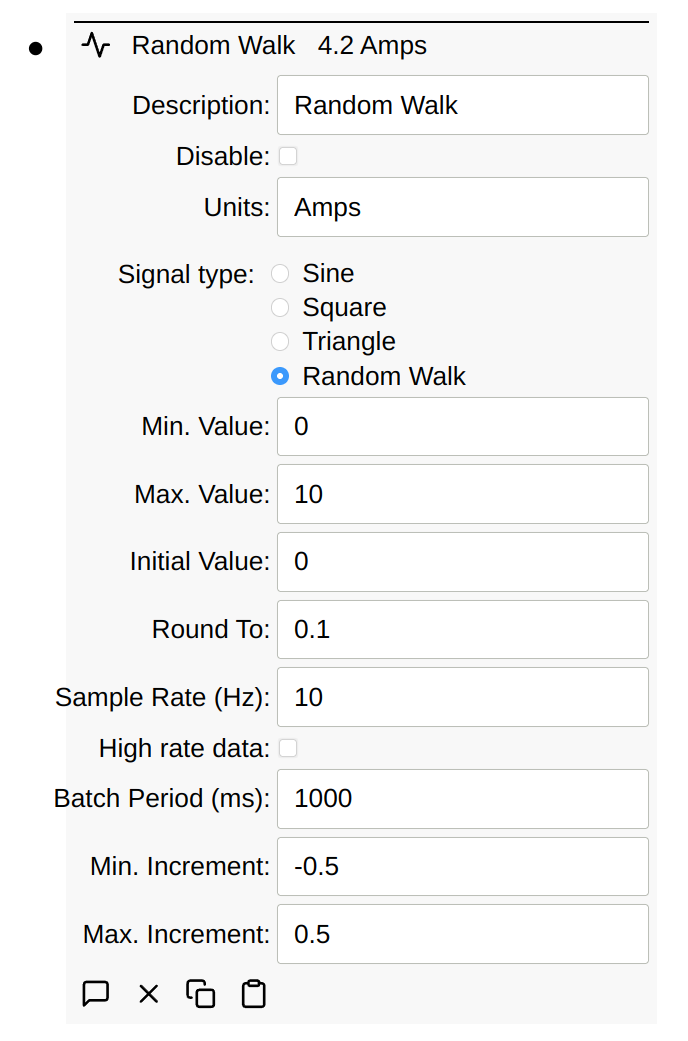
Most of the parameters are self-explanatory. With a Random Walk, you typically need to enter a negative number for the minimum. Increment as shown above. This causes the negative number generated to be negative roughly half the time.
The rounding can also be used to generate binary signals. Imagine a signal generator with these settings:
Max. value= 1Min. value= 0Initial value= 0Round to= 1Min. increment= -7Max. increment= 3Sample Rate= 20 milliseconds
Due to min/max/round to options, this is a binary value, either 0 or 1, biased
toward 0 (due to min/max increment options). This could be useful for
simulating binary switches or something like it. Effectively, this will hold the
value for at least 20m and picks a random number between -7 and 3. Due to
rounding, if value is currently 0, there’s a 25% chance it becomes 1. If 1,
there’s a 65% chance it becomes 0. This means that the value will be 0 roughly
91.25% (= 75% + (1 - 75%) * 65%) of the time.
Schema
Below is an export of several types of signal generator nodes:
children:
- id: 2556a696-a7af-4138-a899-1df6a895aab0
type: signalGenerator
points:
- type: batchPeriod
value: 1000.0
- type: description
text: Variable pulse width
- type: disabled
- type: frequency
value: 1.0
- type: initialValue
text: "0"
- type: maxIncrement
value: 3.0
- type: maxValue
value: 1.0
- type: minIncrement
value: -7.0
- type: minValue
text: "0"
- type: roundTo
value: 1.0
- type: sampleRate
value: 5.0
- type: signalType
text: random walk
- type: units
text: Amps
- type: value
value: 1.0
- id: b67f8ef6-4607-42c9-ab59-9b5ad91af213
type: signalGenerator
points:
- type: batchPeriod
value: 1000.0
- type: description
text: Triangle
- type: disabled
- type: frequency
value: 1.0
- type: initialValue
text: "0"
- type: maxIncrement
value: 0.5
- type: maxValue
value: 10.0
- type: minIncrement
value: 0.1
- type: minValue
text: "0"
- type: sampleRate
value: 100.0
- type: signalType
text: triangle
- type: value
value: 6.465714272450723e-12
- id: e2e6b79a-1d72-475e-a7f4-dfc30b427c91
type: signalGenerator
points:
- type: batchPeriod
value: 1000.0
- type: description
text: Square
- type: disabled
- type: frequency
value: 1.0
- type: initialValue
text: "0"
- type: maxValue
value: 10.0
- type: minValue
text: "0"
- type: sampleRate
value: 100.0
- type: signalType
text: square
- type: value
value: 10.0
- id: fffe6e4e-3887-4eba-9192-e34562940292
type: signalGenerator
points:
- type: batchPeriod
value: 1000.0
- type: description
text: Sine
- type: disabled
- type: frequency
value: 1.0
- type: initialValue
text: "0"
- type: maxValue
value: 10.0
- type: minValue
text: "0"
- type: sampleRate
value: 100.0
- type: signalType
text: sine
- type: value
value: 4.999999999989843
- id: a8e1648c-8d07-448b-b16c-44353ab0fd93
type: signalGenerator
points:
- type: batchPeriod
value: 1000.0
- type: description
text: Random Walk
- type: disabled
- type: frequency
value: 1.0
- type: initialValue
text: "0"
- type: maxIncrement
value: 0.5
- type: maxValue
value: 10.0
- type: minIncrement
value: -0.5
- type: minValue
text: "0"
- type: roundTo
value: 0.1
- type: sampleRate
value: 10.0
- type: signalType
text: random walk
- type: units
text: Amps
- type: value
value: 9.1
Synchronization
Simple IoT provides for synchronized upstream connections via NATS or NATS over WebSocket.
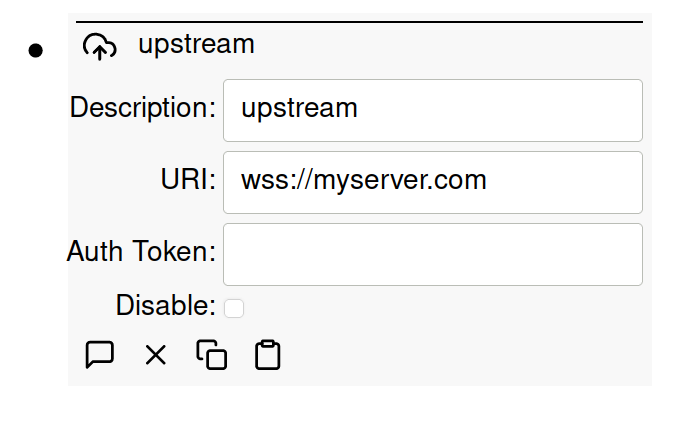
To create an upstream sync, add a sync node to the root node on the downstream
instance. If your upstream server has a name of myserver.com, then you can use
the following connections URIs:
nats://myserver.com:4222(4222 is the default NATS port)ws://myserver.com(WebSocket unencrypted connection)wss://myserver.com(WebSocket encrypted connection)
IP addresses can also be used for the server name.
Auth token is optional and needs to be configured in an environment variable for the upstream server. If your upstream is on the public internet, you should use an auth token. If both devices are on an internal network, then you may not need an auth token.
Typically, wss are simplest for servers that are fronted by a web server like
Caddy that has TLS certs. For internal connections, nats or ws connections
are typically used.
Occasionally, you might also have edge devices on networks where NATS outgoing
connections on port 4222 are blocked. In this case, it’s handy to be able to use
the wss connection, which just uses standard HTTP(S) ports.
Videos
There are also several videos that demonstrate upstream connections:
Simple IoT upstream synchronization support
Simple IoT Integration with PLC Using Modbus
Update
The Simple IoT update client facilitates updating software. Currently, it is designed to download images for use by the Yoe Updater. The process can be executed manually, or there are options to automatically download and install new updates.
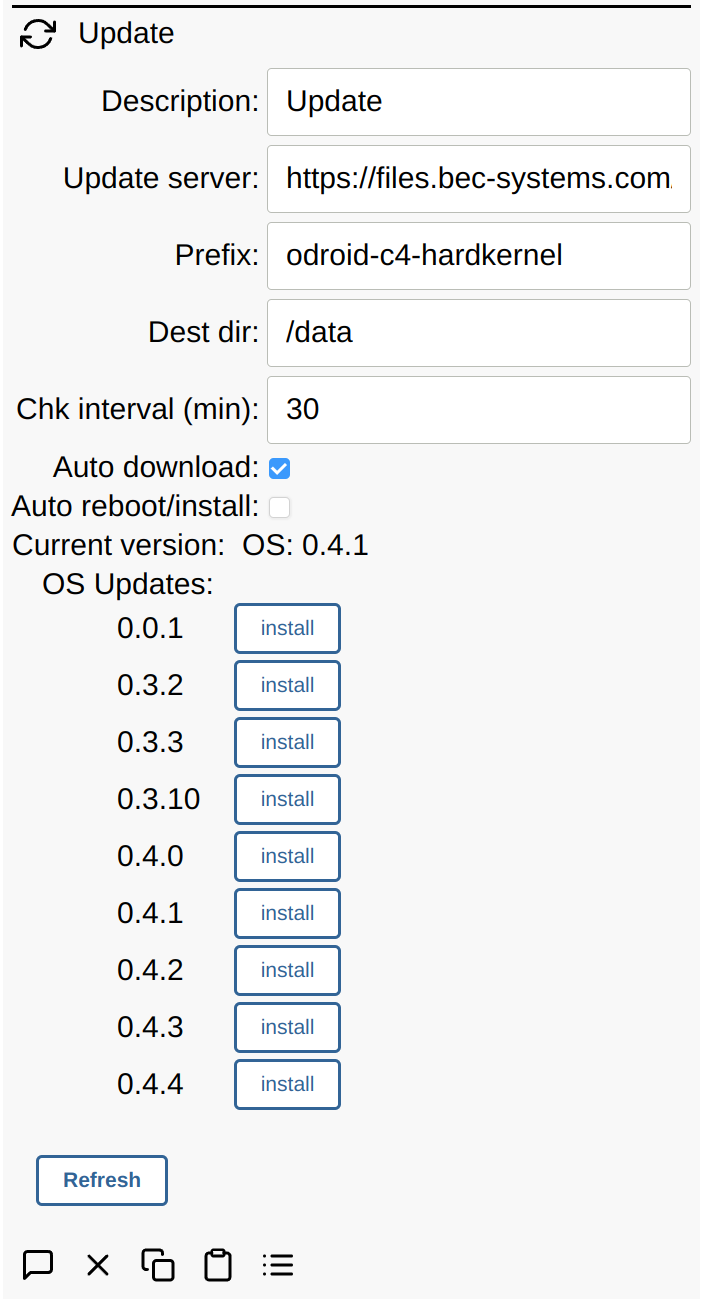
There are several options:
- Update server: HTTP server that contains the following files:
- files.txt: contains a list of update files on the server
- update files named:
<prefix>_<version>.updversionshould follow Semantic Versioning:MAJOR.MINOR.PATCHprefixmust match what the updater on the target device is expecting typically host/machine name.
prefix: described above - typically host/machine name. This is auto detected on first startup, but can be changed if necessary.Dest dir: Destination directory for downloaded updates. Defaults to/data.Chk interval: time interval at which the client checks for new updates.Auto download: option to periodically check the server for new updates and download the latest version.Auto reboot/install: option to auto install/reboot if a new version is detected and downloaded.
USB
Browser
The browser client enables control and configuration of the
Yoe Kiosk Browser as it is
when installed as part of Yoe Distro. On changing the configuration, changes are
saved to /etc/default/yoe-kiosk-browser for the browser and
/etc/default/eglfs.json for EGLFS, and the yoe-kiosk-browser service is
restarted automatically.
Graphing Data
Simple IoT is designed to work with several other applications for storing time series data and viewing this data in graphs.
InfluxDB
InfluxDB is currently the recommended way to store historical data. This database is efficient and can run on embedded platforms like the Raspberry PI as well as desktop and server machines. To connect SIOT to InfluxDB, add a database node and fill in the parameters.
Grafana
Grafana is a very powerful graphing solution that works well with InfluxDB. Although InfluxDB has its own web interface and graphing capability, generally we find Grafana to be more full featured and easier to use.
Changing the Display name (labels) in Grafana
Often with an Influx query, we’ll get trace display names that look like the below:
Often, much of this data is irrelevant or redundant with the query. One way to change the label is with an Override:
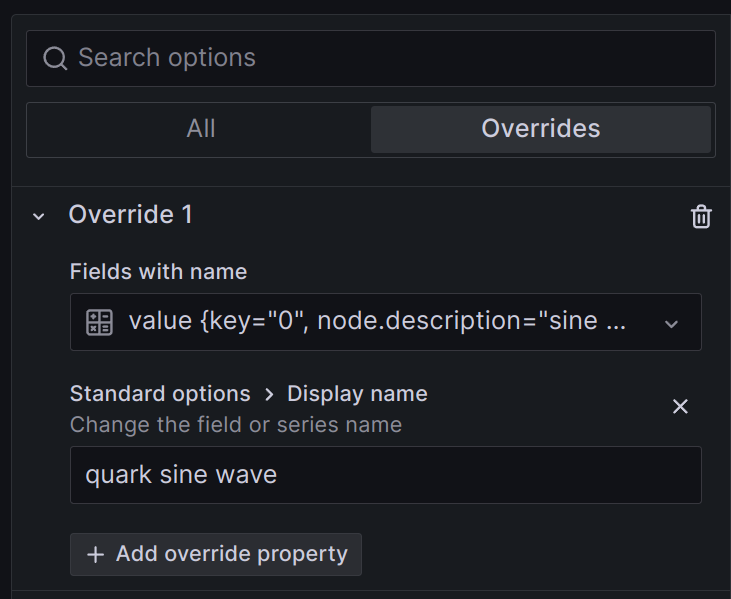
This can be tedious to set up and maintain.
Often a better way is to
add tags
to the nodes generating the data and then display the node tags in the display
name by using the Influx map function.
from(bucket: "siot")
|> range(start: v.timeRangeStart, stop:v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "points" and
r._field == "value" and
r.type == "value")
|> filter(fn: (r) => r["node.type"] == "signalGenerator")
|> map(fn: (r) => ({_value:r._value, _time:r._time, _field:r["node.tag.machine"] + ":" + r["node.description"]}))
In this case we are displaying the node machine tag and description. The result is very nice:
Configuration
Environment variables
Environment variables are used to control various aspects of the application. The following are currently defined:
- General
SIOT_HTTP_PORT: HTTP network port the SIOT server attaches to (default is 8118)SIOT_DATA: directory where any data is storedSIOT_AUTH_TOKEN: auth token used for NATS and HTTP device API, default is blank (no auth)OS_VERSION_FIELD: the field in/etc/os-releaseused to extract the OS version information. Default isVERSION, which is common in most distros. The Yoe Distribution populatesVERSION_IDwith the update version, which is probably more appropriate for embedded systems built with Yoe. See ref/version.
- NATS configuration
SIOT_NATS_PORT: Port to run NATS on (default is 4222 if not set)SIOT_NATS_HTTP_PORT: Port to run NATS monitoring interface (default is 8222)SIOT_NATS_SERVER: defaults to nats://127.0.0.1:4222SIOT_NATS_TLS_CERT: points to TLS certificate file. If not set, TLS is not used.SIOT_NATS_TLS_KEY: points to TLS certificate keySIOT_NATS_TLS_TIMEOUT: Configure the TLS upgrade timeout. NATS defaults to a 0.5 second timeout for TLS upgrade, but that is too short for some embedded systems that run on low end CPUs connected over cellular modems (we’ve see this process take as long as 4 seconds). See NATS documentation for more information.SIOT_NATS_WS_PORT: Port to run NATS WebSocket (default is 9222, set to 0 to disable)
- Particle.io
SIOT_PARTICLE_API_KEY: key used to fetch data from Particle.io devices running Simple IoT firmware
Configuration export
Nodes can be exported to a YAML file. This is a useful to:
- Back up the current configuration
- Dump node data for debugging
- Transfer a configuration or part of a configuration from one instance to another
To export the entire tree:
siot export > backup.yaml
A subset of the tree can be exported by specifying the node ID:
siot export -nodeID 9d7c1c03-0908-4f8b-86d7-8e79184d441d > export.yaml
Configuration import
Nodes defined in a YAML file can be imported into a running SIOT instance using
the CLI, or the Go API. When using the CLI, the import file must be specified on
STDIN. If there are any node IDs in the import they are mapped to new IDs to
eliminate any possibility of ID conflicts if the config is imported into
multiple systems with a common upstream sync, etc.
If nodes reference each other (for instance a rule condition and a Modbus node), then friendly IDs can be used to make it easy to edit and reference. These friendly IDs will be replaced by a common UUID during import.
To import nodes at a specific location (typically a group), then you can specify the parent node ID. This ID can be obtained by expanding the node and clicking the copy button. This will put the ID into your system copy buffer.
siot import -parentID 9d7c1c03-0908-4f8b-86d7-8e79184d441d < import.yaml
If you want to wipe out any existing state and restore a SIOT to a known state,
you can run an import with the -parentID set to root. It is highly
recommended you restart SIOT after this is done to minimize the chance of any
code still running that caches the root ID which has now changed.
siot import -parentID root < backup.yaml
Again, by default, the import command will create new IDs to minimize the chance
of any ID conflicts. If you want to preserve the IDs in the YAML file, you can
specify the -preserveIDs option - WARNING, use this option with caution.
Importing a backup to root with -preserveIDs is a handy way to restore a
system to a known previous state. However, new nodes that don’t exist in the
backup will not be deleted - the import only adds nodes/points.
If authentication or a different server is required, this can be specified through command line arguments or the following environment variables (see descriptions above):
SIOT_NATS_SERVERSIOT_AUTH_TOKEN
It is easy to make a mess with the import command, so think through what you are doing first. SIOT does not prevent you from making a mess!
siot import --help for more details.
Example YAML file:
nodes:
- type: group
points:
- type: description
text: "group 1"
children:
- type: variable
points:
- type: description
text: var 1
- type: value
value: 10
Status
The Simple IoT project is still in a heavy development phase. Most of the core concepts are stable, but APIs, packet formats, and implementation will continue to change for some time yet. SIOT has been used in several production systems to date with good success, but be prepared to work with us (report issues, help fix bugs, etc.) if you want to use it now.
Handling of high rate sensor data
Currently each point change requires quite a bit computation to update the HASH values in upstream graph nodes. For repetitive data, this is not necessary as new values are continually coming in, so we will at some point make an option to specify points values as repetitive. This will allow SIOT to scale to more devices and higher rate data.
User Interface
The web UI is currently polling the SIOT backend every 4 seconds via HTTP. This works OK for small datasets, but uses more data than necessary and has a latency of up to 4 seconds. Long term we will run a NATS client in the frontend over a WebSocket so the UI response is real-time and new data gets pushed to the browser.
Security
Currently, and device that has access to the system can write or write to any data in the system. This may be adequate for small or closed systems, but for larger systems, we need per-device authn/authz. See issue #268, PR #283, and our security document for more information.
Errata
Any issues we find during testing we log in GitHub issues, so if you encounter something unexpected, please search issues first. Feel free to add your observations and let us know if an issues is impacting you. Several issues to be aware of:
- We don’t handle loops in the graph tree yet. This will render the instance unusable and you’ll have to clean the database and start over.
Frequently Asked Questions
Q: How is SIOT different than Home Assistant, OpenHAB, Domoticz, etc.?
Although there may be some overlap and Simple IoT may eventually support a number of off the shelf consumer IoT devices, the genesis, and intent of the project is for developing IoT products and the infrastructure required to support them.
Q: How is SIOT different than Particle.io, etc.?
Particle.io provides excellent infrastructure to support their devices and solve many of the hard problems such as remote firmware update, getting data securely from device to cloud, and efficient data bandwidth usage. But, they don’t provide a way to provide a user facing portal for a product that customers can use to see data and interact with the device.
Q: How is SIOT different than AWS/Azure/GCP/… IoT?
SIOT is designed to be simple to develop and deploy without a lot of moving parts. We’ve reduced an IoT system to a few basic concepts that are exactly the same in the cloud and on edge devices. This symmetry is powerful and allows us to easily implement and move functionality wherever it is needed. If you need Google Scale, SIOT may not be the right choice; however, for smaller systems where you want a system that is easier to develop, deploy, and maintain, consider SIOT.
Q: Can’t NATS JetStream do everything SIOT does?
This is a good question and I’m not sure yet. NATS has some very interesting features like JetStream which can queue data and store data in a key-value store and data can be synchronized between instances. NATS also has a concept of leaf-nodes, which conceptually makes sense for edge/gateway connections. JetStream is optimized for data flowing in one direction (ex: orders through fulfillment). SIOT is optimized for data flowing in any direction and data is merged using data structures with CRDT (conflict-free replicated data types) properties. SIOT also stores data in a DAG (directed acyclic graph) which allows a node to be a child of multiple nodes, which is difficult to do in a hierarchical namespace. Additionally, each node is defined by an array of points and modifications to the system are communicated by transferring points. SIOT is a batteries included complete solution for IoT solutions, including a web framework, clients for various types of IO (ex: Modbus) and cloud services (ex: Twilio). We will continue to explore using more of NATS core functionality as we move forward.
Documentation
Good documentation is critical for any project and to get good documentation, the process to create it must be as frictionless as possible. With this in mind, we’ve structured SIOT documentation as follows:
- Markdown is the primary source format.
- Documentation lives in the same repo as the source code. When you update the code, update the documentation at the same time.
- Documentation is easily viewable in GitHub, or our generated docs site. This allows any snapshot of SIOT to contain a viewable snapshot of the documentation for that revision.
mdbookis used to generate the documentation site.- All diagrams are stored in a
single draw.io
file. This allows you to easily see what diagrams are available and easily
copy pieces from existing diagrams to make new ones. Then generate a PNG for
the diagram in the
images/directory in the relevant documentation directory.
Vision
This document attempts to outlines the project philosophy and core values. The basics are covered in the readme. As the name suggests, a core value of the project is simplicity. Thus, any changes should be made with this in mind. Although this project has already proven useful on several real-world project, it is a work in progress and will continue to improve. As we continue to explore and refine the project, many things are getting simpler and more flexible. This process takes time and effort.
“When you first start off trying to solve a problem, the first solutions you come up with are very complex, and most people stop there. But if you keep going, and live with the problem and peel more layers of the onion off, you can often times arrive at some very elegant and simple solutions.” - Steve Jobs
Guiding principles
- Simple concepts are flexible and scale well.
- IoT systems are inherently distributed, and distributed systems are hard.
- There are more problems to solve than people to solve them, thus it makes sense to collaborate on the common technology pieces.
- There are a lot of IoT applications that are not Google scale (10-1000 device range).
- There is significant opportunity in the long tail of IoT, which is our focus.
- There is value in custom solutions (programming vs drag-n-drop).
- There is value in running/owning our own platform.
- A single engineer should be able to build and deploy a custom IoT system.
- We don’t need to spend excessive amounts of time on operations. For smaller deployments, we deploy one binary to a cloud server and we are done with operations. We don’t need 20 microservices when one monolith will work just fine.
- For many applications, a couple of hours of down time is not the end of the world. Thus, a single server that can be quickly rebuilt as needed is adequate and in many cases more reliable than complex systems with many moving parts.
Technology choices
Choices for the technology stack emphasize simplicity, not only in the language, but just as important, in the deployment and tooling.
- Backend
- Go
- Simple language and deployment model
- Nice balance of safety + productivity
- Excellent tooling and build system
- See this thread for more discussion/information
- Go
- Frontend
- Single Page Application (SPA) architecture
- Fits well with real-time applications where data is changing all the time
- Easier to transition to Progressive Web Apps (PWA)
- Elm
- Nice balance of safety + productivity
- Excellent compiler messages
- Reduces possibility for run time exceptions in browser
- Does not require a huge/complicated/fragile build system typical in JavaScript frontends.
- excellent choice for SPAs
- elm-ui
- What if you never had to write CSS again?
- Fun, yet powerful way to lay out a user interface and allows you to efficiently make changes and get the layout you want.
- Single Page Application (SPA) architecture
- Database
- SQLite
- See Store
- Eventually support multiple database backends depending on scaling/admin needs
- SQLite
- Cloud Hosting
- Any machine that provides ability run long-lived Go applications
- Any MAC/Linux/Windows/rPI/Beaglebone/Odroid/etc. computer on your local network.
- Cloud VMs: Digital Ocean, Linode, GCP compute engine, AWS EC2, etc. Can easily host on a $5/mo instance.
- Edge Devices
- Any device that runs Linux (rPI, Beaglebone-black, industrial SBCs, your custom hardware …)
In our experience, simplicity and good tooling matter. It is easy to add features to a language, but creating a useful language/tooling that is simple is hard. Since we are using Elm on the frontend, it might seem appropriate to select a functional language like Elixir, Scala, Clojure, Haskell, etc. for the backend. These environments are likely excellent for many projects, but are also considerably more complex to work in. The programming style (procedural, functional, etc.) is important, but other factors such as simplicity/tooling/deployment are also important, especially for small teams who don’t have separate staff for backend/frontend/operations. Learning two simple languages (Go and Elm) is a small task compared to dealing with huge languages, fussy build tools, and complex deployment environments.
This is just a snapshot in time - there will likely be other better technology choices in the future. The backend and frontend are independent. If either needs to be swapped out for a better technology in the future, that is possible.
Architecture
This document describes how the Simple IoT project fulfills the basic requirements as described in the top level README.
There are two levels of architecture to consider:
- System: how multiple SIOT instances and other applications interact to form a system.
- Application: how the SIOT application is structured.
- Clients: all about SIOT clients where most functionality is implemented.
High Level Overview
Simple IoT functions as a collection of connected, distributed instances that communicate via NATS. Data in the system is represented by nodes which contain an array of points. Data changes are communicated by sending points within an instance or between instances. Points in a node are merged such that newer points replace older points. This allows granular modification of a node’s properties. Nodes are organized in a DAG (directed acyclic graph). This graph structure defines many properties of the system such as what data users have access to, the scope of rules and notifications, and which nodes external services apply to. Most functionality in the system is implemented in clients, which subscribe and publish point changes for nodes they are interested in.
System Architecture
Contents
IoT Systems are distributed systems
IoT systems are inherently distributed where data needs to be synchronized between a number of different systems including:
- Cloud (one to several instances depending on the level of reliability desired)
- Edge devices (many instances)
- User Interface (phone, browser)
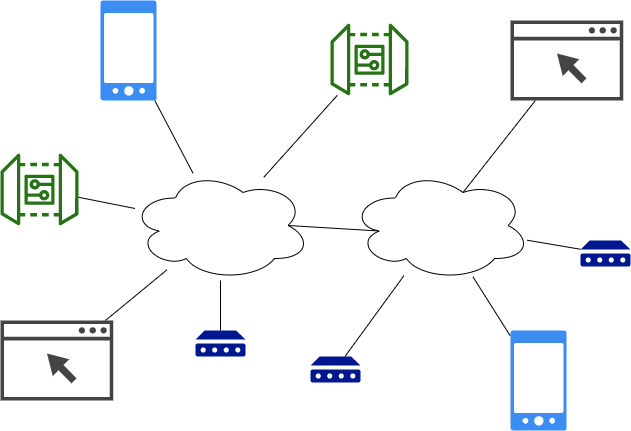
Typically, the cloud instance stores all the system data, and the edge, browser, and mobile devices access a subset of the system data.
Extensible architecture
Any siot app can function as a standalone, client, server or both. As an
example, siot can function both as an edge (client) and cloud apps (server).
- Full client: full SIOT node that initiates and maintains connection with another SIOT instance on a server. Can be behind a firewall, NAT, etc.
- Server: needs to be on a network that is accessible by clients
We also need the concept of a lean client where an effort is made to minimize the application size to facilitate updates over IoT cellular networks where data is expensive.
Device communication and messaging
In an IoT system, data from sensors is continually streaming, so we need some type of messaging system to transfer the data between various instances in the system. This project uses NATS.io for messaging. Some reasons:
- Allows us to push real-time data to an edge device behind a NAT, on cellular network, etc. - no public IP address, VPN, etc. required.
- Is more efficient than HTTP as it shares one persistent TCP connection for all messages. The overhead and architecture is similar to MQTT, which is proven to be a good IoT solution. It may also use less resources than something like observing resources in CoAP systems, where each observation requires a separate persistent connection.
- Can scale out with multiple servers to provide redundancy or more capacity.
- Is written in Go, so possible to embed the server to make deployments simpler for small systems. Also, Go services are easy to manage as there are no dependencies.
- Focus on simplicity - values fit this project.
- Good security model.
For systems that only need to send one value several times a day, CoAP is probably a better solution than NATS. Initially we are focusing on systems that send more data - perhaps 5-30MB/month. There is no reason we can’t support CoAP as well in the future.
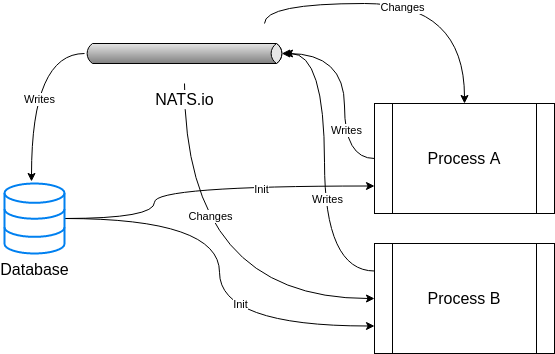
Data modification
Where possible, modifying data (especially nodes) should be initiated over NATS vs direct db calls. This ensures anything in the system can have visibility into data changes. Eventually we may want to hide db operations that do writes to force them to be initiated through a NATS message.
Simple, Flexible data structures
As we work on IoT systems, data structures (types) tend to emerge. Common data structures allow us to develop common algorithms and mechanism to process data. Instead of defining a new datatype for each type of sensor, define one type that will work with all sensors. Then the storage (both static and time-series), synchronization, charting, and rule logic can stay the same and adding functionality to the system typically only involves changing the edge application and the frontend UI. Everything between these two end points can stay the same. This is a very powerful and flexible model as it is trivial to support new sensors and applications.
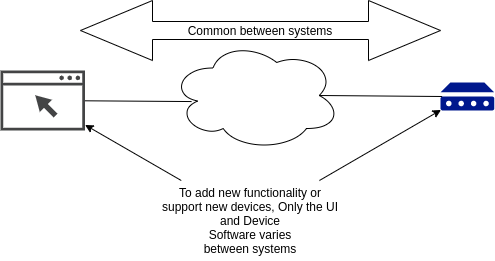
See Data for more information.
Node Tree
The same Simple IoT application can run in both the cloud and device instances. The node tree in a device would then become a subset of the nodes in the cloud instance. Changes can be made to nodes in either the cloud or device and data is synchronized in both directions.
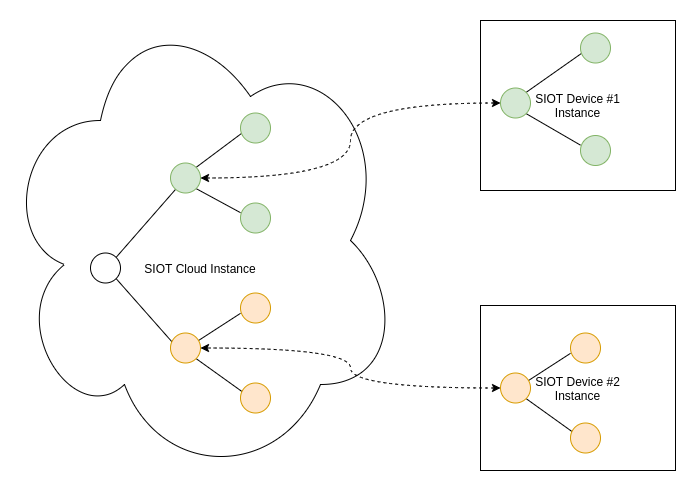
The following diagram illustrates how nodes might be arranged in a typical system.
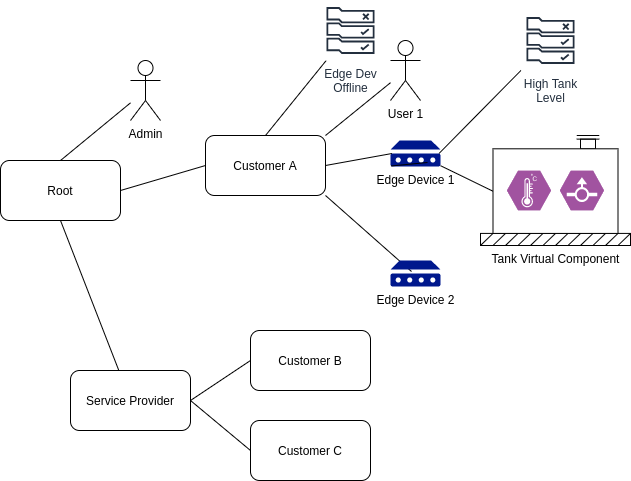
A few notes this structure of data:
- A user has access to its child nodes, parent nodes, and parent node descendants (parents, children, siblings, nieces/nephews).
- Likewise, a rule node processes points from nodes using the same relationships described above.
- A user can be added to any node. This allows permissions to be granted at any level in the system.
- A user can be added to multiple nodes.
- A node admin user can configure nodes under it. This allows a service provider to configure the system for their own customers.
- If a point changes, it triggers rules of upstream nodes to run (perhaps paced to some reasonable interval)
- The Edge Dev Offline rule will fire if any of the Edge devices go offline. This allows us to only write this rule once to cover many devices.
- When a rule triggers a notification, the rule node and any upstream nodes can optionally notify its users.
The distributed parts of the system include the following instances:
- Cloud (could be multiple for redundancy). The cloud instances would typically store and synchronize the root node and everything under it.
- Edge Devices (typically many instances (1000’s) connected via low bandwidth cellular data). Edge instances would store and synchronize the edge node instance and descendants (ex Edge Device 1)
- Web UI (potentially dozens of instances connected via higher bandwidth browser connection).
As this is a distributed system where nodes may be created on any number of connected systems, node IDs need to be unique. A unique serial number or UUID is recommended.
Application Architecture
Contents
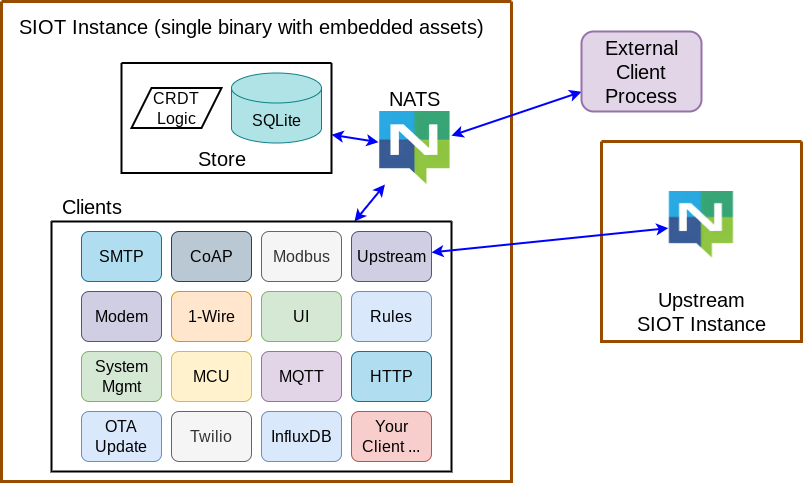
The Simple IoT Go application is a single binary with embedded assets. The database and NATS server are also embedded by default for easy deployment. There are five main parts to a Simple IoT application:
- NATS Message Bus: all data goes through this making it very easy to observe the system.
- Store: persists the data for the system, merges incoming data, maintains node hash values for synchronization, rules engine, etc. (the rules engine may eventually move to a client)
- Clients: interact with other devices/systems such as Modbus, 1-wire, etc. This is where most of the functionality in a SIOT system lives, and where you add your custom functionality. Clients can exist inside the Simple IoT application or as external processes written in any language that connect via NATS. Clients are represented by a node (and optionally child nodes) in the SIOT store. When a node is updated, its respective clients are updated with the new information. Likewise, when a client has new information, it sends that out to be stored and used by other nodes/instances as needed.
- HTTP API: provides a way for HTTP clients to interact with the system.
- Web UI: Provides a user interface for users to interact with the system. Currently it uses the HTTP API, but will eventually connect directly to NATS.
The simplicity of this architecture makes it easy to extend with new functionality by writing a new client. Following the constraints of storing data as nodes and points ensures all data is visible and readable by other clients, as well as being automatically synchronized to upstream instances.
Application Lifecycle
Simple IoT uses the
Run()/Stop()
pattern for any long running processes. With any long running process, it is
important to not only Start it, but also to be able to cleanly Stop it. This is
important for testing, but is also good practice. Nothing runs forever so we
should never operate under this illusion. The
oklog/run packaged is used to start and
shutdown these processes concurrently. Dependencies between processes should be
minimized where possible through retries. If there are hard dependencies, these
can be managed with WaitStart()/WaitStop() functions. See
server.go
for an example.
NATS lends itself very well to a decoupled application architecture because the NATS clients will buffer messages for some time until the server is available. Thus, we can start all the processes that use a NATS client without waiting for the server to be available first.
Long term, a NATS API that indicates the status of various parts (rules engine, etc.) of the system would be beneficial. If there are dependencies between processes, this can be managed inside the process instead of in the code that starts/stops the processes.
NATS Integration
The NATS API details the NATS subjects used by the system.
Echo concerns
Any time you potentially have two sources modifying the same resource (a node), you need to be concerned with echoed messages. This is a common occurrence in Simple IoT. Because another resource may modify a node, typically a client needs to subscribe to the node messages as well. This means when it sends a message, it will typically be echoed back. See the client documentation for ideas on how to handle the echo problem.
The
server.NewServer
function returns a NATS connection. This connection is used throughout the
application and does not have the NoEcho option set.
User Interface
Currently, the User Interface is implemented using a Single Page Architecture (SPA) Web Application. This keeps the backend and frontend implementations mostly independent. See User Interface and Frontend for more information.
There are many web architectures to chose from and web technology is advancing at a rapid pace. SPAs are not in vogue right now and more complex architectures are promoted such as Next.js, SveltKit, Deno Fresh, etc. Concerns with SPAs include large initial load and stability (if frontend code crashes, everything quits working). These concerns are valid if using JavaScript, but with Elm these concerns are minimal as Elm compiles to very small bundles, and run time exceptions are extremely rare. This allows us to use a simple web architecture with minimal coupling to the backend and minimal build complexity. And it will be a long time until we write enough Elm code that bundle size matters.
A decoupled SPA UI architecture is also very natural in Simple IoT, as IoT systems are inherently distributed. The frontend is just another client, much the same as a separate machine learning process, a downstream instance, a scripting process, etc.
Simple IoT Clients
Contents
Most functionality in Simple IoT is implemented in Clients.
Each client can be configured by one or more nodes in the SIOT store graph. These nodes may be created by a user, a process that detects new plug and play hardware, or other clients.
A client interacts with the system by listening for new points it is interested in and sending out points as it acquires new data.
Creating new clients
See Development for information on how to set up a development system.
Simple IoT provides utilities that assist in creating new clients. See the Go package documentation for more information. A client manager is created for each client type. This manager instantiates new client instances when new nodes are detected and then sends point updates to the client. Two levels of nodes are currently supported for client configuration. An example of this would be a Rule node that has Condition and Action child nodes.
A “disabled” option is useful and should be considered for every new client.
Creating a new client typically requires the following steps:
- Add any new node and points types to
schema.go,Node.elm, andPoint.elm. Please try to reuse existing point types when possible. - Create a new client in
client/directory. A client is defined by a type that satisfies theClient interface. A constructor must also be defined that is passed toNewManagerand a struct that represents the client data. The name of the struct must match the node type - for instance a node of typecanBusneeds to be defined by a struct namedCanBus. Additionally, each field of the client struct must have point tags. This allows us to automatically create and modify client structs from arrays of node points. - Create a new manager for the client in
client/client.go - Create an Elm UI for the client in
frontend/src/Components/ - Create plumbing for new
NodeXYZinfrontend/src/Pages/Home_.elm. Note, this can likely be improved a lot.
It is easiest to copy one of the existing clients to start. The NTP client is relatively simple and may be a good example.
Client life-cycle
It is important the clients cleanly implement the Run()/Stop() pattern and shut down cleanly when Stop() is called releasing all resources. If nodes are added or removed, clients are started/stopped. Additionally, if a child node of a client config is added or removed, the entire client is stopped and then restarted. This relieves the burden on the client from managing the addition/removal of client functionality. Thus, it is very important that clients stop cleanly and release resources in case they are restarted.
Message echo
Clients need to be aware of the “echo” problem as they typically subscribe as
well as publish to the points subject for the nodes they manage. When they
publish to these subjects, these messages will be echoed back to them. There are
several solutions:
- Create a new NATS connection for the client with the
NoEchooption set. For this to work, each client will need to establish its own connection to the server. This may not work in cases where subjects are aliased into authenticated subject namespaces. - Inspect the
PointOriginfield - if is blank, then it was generated by the node that owns the point and does not need to be processed by the client generating the data for that node. If is not blank, then the Point was generated by a user, rule, or something other than the client owning the node and must be processed. This may not always work - example: user is connected to a downstream instance and modifies a point that then propagates upstream- it may get echoed back to an authenticated client.
- (investigation stage) A NATS messages header can be populated with the ID of the client that sent the message. If it is an authenticated client, then the message will not be echoed on the authenticated client subject namespace of the same ID. This information is not stored, so cannot be used for auditing purposes.
The SIOT client manager filters out points for the following two scenarios:
- A point with the same ID as the client and Origin set to a blank string.
- A point received for a client where Origin matches the client root node ID.
Thus, if you want to set a point in one client and get that point to another node client, you must set the Origin field. This helps ensure that the Origin field is used consistently as otherwise stuff won’t work.
This gets a little tricky for clients that manage a node and its children (for instance the rule client - it has condition and action child nodes). If we follow the following rule:
Clients must set the point Origin field for any point sent to anything other than its root node.
If we following the above rule, then things should work. We may eventually provide clients with a function to send points that handles this automatically, but for now it is manual.
See also tracking who made changes.
Development
Go Package Documentation
The Simple IoT source code is available on GitHub.
Simple IoT is written in Go. Go package documentation is available.
Building Simple IoT
Requirements:
- Go
- Node/NPM
Simple IoT build has currently been testing on Linux and MacOS systems. See
envsetup.sh
for scripts used in building.
To build:
source envsetup.shsiot_setupsiot_build
Developing Simple IoT
npm install -g run-pty. envsetup.shsiot_setupsiot_watch
The siot_watch command can be used when developing Simple IoT. This does the
following:
- Starts
elm-watchon the Elm code.elm-watchwill automatically update the UI without losing state any time an Elm file changes. - Runs the Go backend and rebuilds it anytime a Go module changes (only tested on Linux and MacOS, but should be easy to set up Windows as well)
Both of the above are run in a run-pty
wrapper, which allows you to see the output of either process. The output of the
Elm compile is displayed in the browser, so it is rarely necessary to view the
elm-watch side.
Using Simple IoT as a library
Simple IoT can be used a library for your custom application. The SIOT main.go illustrates how to start the SIOT server, and add clients. You can do this from any Go application. With a few lines of code, this gives you a lot of functionality including a NATS server.
Developing a new SIOT client
Most SIOT functionality is implemented in clients. See the client documentation for more information.
Customizing the UI
Currently, there is no simple way to customize the SIOT UI when using SIOT as a library package. Forking and changing the SIOT Elm code is probably the simplest way if you want to make a small change now.
In the future, we plan to provide an API for passing in a custom UI to the SIOT Server. You can also implement a custom HTTP client that serves up a custom UI.
Code Organization
Currently, there are a lot of subdirectories. One reason for this is to limit
the size of application binaries when building edge/embedded Linux binaries. In
some use cases, we want to deploy app updates over cellular networks, therefore
we want to keep packages as small as possible. For instance, if we put the
natsserver stuff in the nats package, then app binaries grow a couple MB,
even if you don’t start a NATS server. It is not clear yet what Go does for dead
code elimination, but at this point, it seems referencing a package increases
the binary size, even if you don’t use anything in it. (Clarification welcome!)
For edge applications on Embedded Linux, we’d eventually like to get rid of net/HTTP, since we can do all network communications over NATS. We’re not there yet, but be careful about pulling in dependencies that require net/HTTP into the NATS package, and other low level packages intended for use on devices.
Directories
See Go docs directory descriptions
Coding Standards
Please run siot_test from envsetup.sh before submitting pull requests. All
code should be formatted and linted before committing.
Please configure your editor to run code formatters:
- Go:
goimports - Elm:
elm-format - Markdown:
prettier(note, there is a.prettierrcin this project that configures prettier to wrap markdown to 80 characters. Whether to wrap markdown or not is debatable, as wrapping can make diffs harder to read, but Markdown is much more pleasant to read in an editor if it is wrapped. Since more people will be reading documentation than reviewing, let’s optimize for the reading in all scenarios - editor, GitHub, and generated docs)
Pure Go
We plan to keep the main Simple IoT application a pure Go binary if possible. Statically linked pure Go has huge advantages:
- You can easily cross compile to any target from any build machine.
- Blazing fast compile times
- Deployment is dead simple – zero dependencies. Docker is not needed.
- You are not vulnerable to security issues in the host systems SSL/TLS libraries. What you deploy is pretty much what you get.
- Although there is high quality code written in C/C++, it is much easier to write safe, reliable programs in Go. Long term there is much less risk using a Go implementation of about anything – especially if it is widely used.
- Go’s network programming model is much simpler than about anything else. Simplicity == less bugs.
Once you link to C libraries in your Go program, you forgo many of the benefits of Go. The Go authors made a brilliant choice when they chose to build Go from the ground up. Yes, you loose the ability to easily use some of the popular C libraries, but what you gain is many times more valuable.
Running unit tests
There are not a lot of unit tests in the project yet, but below are some examples of running tests:
- test everything:
go test -race ./... - test only client directory:
go test -race ./client - Run only a specific:
go test -race ./client -run BackoffTest(run takes a RegEx) siot_testruns tests as well as vet/lint, frontend tests, etc.
The leading ./ is important, otherwise Go things you are giving it a package
name, not a directory. The ... tells Go to recursively test all sub
directories.
Document and test during development
It is much more pleasant to write documentation and tests as you develop, rather than after the fact. These efforts add value to your development if done concurrently. Quality needs to be designed-in, and leading with documentation will result in better thinking and a better product.
If you develop a feature, please update/create any needed documentation and write any tests (especially end-to-end) to verify the feature works and continues to work.
Data
Contents
See also:
Data Structures
As a client developer, there are two main primary structures:
NodeEdge
and Point. A
Node can be considered a collection of Points.
These data structures describe most data that is stored and transferred in a Simple IoT system.
The core data structures are currently defined in the
data directory for
Go code, and
frontend/src/Api
directory for Elm code.
A Point can represent a sensor value, or a configuration parameter for the
node. With sensor values and configuration represented as Points, it becomes
easy to use both sensor data and configuration in rule or equations because the
mechanism to use both is the same. Additionally, if all Point changes are
recorded in a time series database (for instance InfluxDB), you automatically
have a record of all configuration and sensor changes for a node.
Treating most data as Points also has another benefit in that we can easily
simulate a device. Provide an UI or write a program to modify any point and we
can shift from working on real data to simulating scenarios we want to test.
Edges are used to describe the relationships between nodes as a directed acyclic graph.

Nodes can have parents or children and thus be represented in a hierarchy. To
add structure to the system, you simply add nested Nodes. The Node hierarchy
can represent the physical structure of the system, or it could also contain
virtual Nodes. These virtual nodes could contain logic to process data from
sensors. Several examples of virtual nodes:
- A pump
Nodethat converts motor current readings into pump events. - Implement moving averages, scaling, etc. on sensor data.
- Combine data from multiple sensors
- Implement custom logic for a particular application
- A component in an edge device such as a cellular modem
Like Nodes, Edges also contain a Point array that further describes the relationship between Nodes. Some examples:
- Role the user plays in the node (viewer, admin, etc.)
- Order of notifications when sequencing notifications through a node’s users
- Node is enabled/disabled for instance we may want to disable a Modbus IO node that is not currently functioning.
Being able to arranged nodes in an arbitrary hierarchy also opens up some interesting possibilities such as creating virtual nodes that have a number of children that are collecting data. The parent virtual nodes could have rules or logic that operate off data from child nodes. In this case, the virtual parent nodes might be a town or city, service provider, etc., and the child nodes are physical edge nodes collecting data, users, etc.
The Point Key field constraint
The Point data structure has a Key field that can be used to construct Array
and Map data structures in a node. This is a flexible idea in that it is easy to
transition from a scaler value to an array or map. However, it can also cause
problems if one client is writing key values of "" and another client (say a
rule action) is writing value of "0". One solution is to have fancy logic that
equates "" to "0" on point updates, compares, etc. Another approach is to
consider "" and invalid key value and set key to "0" for scaler values. This
incurs a slight amount of overhead, but leads to more predictable operation and
eliminates the possibility of having two points in a node that mean the same
things.
The Simple IoT Store always sets the Key field to "0" on incoming points if
the Key field is blank.
Clients should be written with this in mind.
Converting Nodes to other data structures
Nodes and Points are convenient for storage and synchronization, but cumbersome
to work with in application code that uses the data, so we typically convert
them to another data structure.
data.Decode,
data.Encode,
and
data.MergePoints
can be used to convert Node data structures to your own custom struct, much
like the Go json package.
Arrays and Maps
Points can be used to represent arrays and maps. For an array, the key field
contains the index "0", "1", "2", etc. For maps, the key field contains
the key of the map. An example:
| Type | Key | Text | Value |
|---|---|---|---|
description | 0 | Node Description | |
ipAddress | 0 | 192.168.1.10 | |
ipAddress | 1 | 10.0.0.3 | |
diskPercentUsed | / | 43 | |
diskPercentUsed | /home | 75 | |
switch | 0 | 1 | |
switch | 1 | 0 |
The above would map to the following Go type:
type myNode struct {
ID string `node:"id"`
Parent string `node:"parent"`
Description string `node:"description"`
IpAddresses []string `point:"ipAddress"`
Switches []bool `point:"switch"`
DiscPercentUsed []float64 `point:"diskPercentUsed"`
}
The
data.Decode()
function can be used to decode an array of points into the above type. The
data.Merge()
function can be used to update an existing struct from a new point.
Best practices for working with arrays
To make changes to an array in UI/Client code when storing the array in a native structure, store a length field as well so you know how long the original array was. After modifying the array, check if the new length is less than the original - if it is, then add a tombstone points to the end so that the deleted points get removed.
Generally it is simplest to send the entire array as a single message any time
any value in it has changed - especially if values are going to be added or
removed. The data.Decode will then correctly handle the array resizing.
Technical details of how data.Decode works with slices
Some consideration is needed when using Decode and MergePoints to decode
points into Go slices. Slices are never allocated / copied unless they are being
expanded. Instead, deleted points are written to the slice as the zero value.
However, for a given Decode call, if points are deleted from the end of the
slice, Decode will re-slice it to remove those values from the slice. Thus,
there is an important consideration for clients: if they wish to rely on slices
being truncated when points are deleted, points must be batched in order such
that Decode sees the trailing deleted points first. Put another way, Decode
does not care about points deleted from prior calls to Decode, so “holes” of
zero values may still appear at the end of a slice under certain circumstances.
Consider points with integer values [0, 1, 2, 3, 4]. If tombstone is set on
point with Key 3 followed by a point tombstone set on point with Key 4,
the resulting slice will be [0, 1, 2] if these points are batched together.
But, if they are sent separately (thus resulting in multiple Decode calls),
the resulting slice will be [0, 1, 2, 0].
Node Topology changes
Nodes can exist in multiple locations in the tree. This allows us to do things like include a user in multiple groups.
Add
Node additions are detected in real-time by sending the points for the new node as well as points for the edge node that adds the node to the tree.
Copy
Node copies are similar to add, but only the edge points are sent.
Delete
Node deletions are recorded by setting a tombstone point in the edge above the node to true. If a node is deleted, this information needs to be recorded, otherwise the synchronization process will simply re-create the deleted node if it exists on another instance.
Move
Move is just a combination of Copy and Delete.
If the any real-time data is lost in any of the above operations, the catch up synchronization will propagate any node changes.
Tracking who made changes
The Point type has an Origin field that is used to track who generated this
point. If the node that owned the point generated the point, then Origin can be
left blank - this saves data bandwidth - especially for sensor data which is
generated by the client managing the node. There are several reasons for the
Origin field:
- Track who made changes for auditing and debugging purposes. If a rule or some process other than the owning node modifies a point, the Origin should always be populated. Tests that generate points should generally set the origin to “test”.
- Eliminate echos where a client may be subscribed to a subject as well as publish to the same subject. With the Origin field, the client can determine if it was the author of a point it receives, and if so simply drop it. See client documentation for more discussion of the echo topic.
Evolvability
One important consideration in data design is the can the system be easily changed. With a distributed system, you may have different versions of the software running at the same time using the same data. One version may use/store additional information that the other does not. In this case, it is very important that the other version does not delete this data, as could easily happen if you decode data into a type, and then re-encode and store it.
With the Node/Point system, we don’t have to worry about this issue because Nodes are only updated by sending Points. It is not possible to delete a Node Point. So it one version writes a Point the other is not using, it will be transferred, stored, synchronized, etc. and simply ignored by version that don’t use this point. This is another case where SIOT solves a hard problem that typically requires quite a bit of care and effort.
Simple IoT Store
We currently use SQLite to implement the persistent store for Simple IoT. Each instance (cloud, edge, etc.) has its own store that must be synchronized with replicas of the data located in other instances.
Reasons for using SQLite
We have evaluated BoltDB, Genji, and various other Go key/value stores in the past and settled on SQLite for the following reasons:
- Reliability: SQLite is very well tested and handles things like program/OS crashes, power failures, etc. It is important that the configuration for a system never become corrupt to the point where it won’t load.
- Stable file format: Dealing with file format changes is not something we want to deal with when we have 100’s of systems in the field. A SQLite file is very portable across time and between systems.
- Pure Go: There is now a pure Go version of SQLite. If more performance is needed or smaller binary size, the native version of SQLite can still be used.
- The relational model: it seems to make sense to store points and nodes in separate tables. This allows us to update points more quickly as it is a separate line in the DB. It also seems like flat data structures are generally a good thing versus deeply nested objects.
- Fast: SQLite does read caching, and other things that make it quite fast.
- Lots of innovation around SQLite: LiteFS, Litestream, etc.
- Multi-process: SQLite supports multiple processes. While we don’t really need this for core functionality, it is very handy for debugging, and there may be instances where you need multiple applications in your stack.
Data Synchronization
See research for information on techniques that may be applicable to this problem.
Typically, configuration is modified through a user interface either in the
cloud, or with a local UI (ex touchscreen LCD) at an edge device. Rules may also
eventually change values that need to be synchronized. As mentioned above, the
configuration of a Node will be stored as Points. Typically the UI for a
node will present fields for the needed configuration based on the Node
Type, whether it be a user, rule, group, edge device, etc.
In the system, the Node configuration will be relatively static, but the points in a node may be changing often as sensor values changes, thus we need to optimize for efficient synchronization of points. We can’t afford the bandwidth to send the entire node data structure any time something changes.
As IoT systems are fundamentally distributed systems, the question of synchronization needs to be considered. Both client (edge), server (cloud), and UI (frontend) can be considered independent systems and can make changes to the same node.
- An edge device with an LCD/Keypad may make configuration changes.
- Configuration changes may be made in the Web UI.
- Sensor values will be sent by an edge device.
- Rules running in the cloud may update nodes with calculated values.
Although multiple systems may be updating a node at the same time, it is very rare that multiple systems will update the same node point at the same time. The reason for this is that a point typically only has one source. A sensor point will only be updated by an edge device that has the sensor. A configuration parameter will only be updated by a user, and there are relatively few admin users, and so on. Because of this, we can assume there will rarely be collisions in individual point changes, and thus this issue can be ignored. The point with the latest timestamp is the version to use.
Real-time Point synchronization
Point changes are handled by sending points to a NATS topic for a node any time it changes. There are three primary instance types:
- Cloud: will subscribe to point changes on all nodes (wildcard)
- Edge: will subscribe to point changes only for the nodes that exist on the instance - typically a handful of nodes.
- WebUI: will subscribe to point changes for nodes currently being viewed - again, typically a small number.
With Point Synchronization, each instance is responsible for updating the node data in its local store.
Catch-up/non real-time synchronization
Sending points over NATS will handle 99% of data synchronization needs, but there are a few cases this does not cover:
- One system is offline for some period of time
- Data is lost during transmission
- Other errors or unforeseen situations
There are two types of data:
- Periodic sensor readings (we’ll call sample data) that is being continuously updated.
- Configuration data that is infrequently updated.
Any node that produces sample data should send values every 10m, even if the value is not changing. There are several reasons for this:
- Indicates the datasource is still alive.
- Makes graphing easier if there is always data to plot.
- Covers the synchronization problem for sample data. A new value will be coming soon, so don’t really need catch-up synchronization for sample data.
Config data is not sent periodically. To manage synchronization of config data,
each edge will have a Hash field that can be compared between instances.
Node hash
The edge Hash field is a hash of:
- Edge point CRCs
- Node points CRCs (except for repetitive or high rate sample points)
- Child edge
Hashfields
We store the hash in the edge structures because nodes (such as users) can
exist in multiple places in the tree.
This is essentially a Merkle DAG - see research.
Comparing the node Hash field allows us to detect node differences. If a
difference is detected, we can then compare the node points and child nodes to
determine the actual differences.
Any time a node point (except for repetitive or high rate data) is modified, the
node’s Hash field is updated, and the Hash field in parents, grand-parents,
etc. are also computed and updated. This may seem like a lot of overhead, but if
the database is local, and the graph is reasonably constructed, then each update
might require reading a dozen or so nodes and perhaps writing 3-5 nodes.
Additionally, non sample-data changes are relatively infrequent.
Initially synchronization between edge and cloud nodes is supported. The edge device will contain an “upstream” node that defines a connection to another instance’s NATS server - typically in the cloud. The edge node is responsible for synchronizing of all state using the following algorithm:
- Occasionally the edge device fetches the edge device root node hash from the cloud.
- If the hash does not match, the edge device fetches the entire node and compares/updates points. If local points need updated, this process can happen all on the edge device. If upstream points need updated, these are simply transmitted over NATS.
- If the node hash still does not match, a recursive operation is started to fetch child node hashes and the same process is repeated.
Hash Algorithm
We don’t need cryptographic level hashes as we are not trying to protect against malicious actors, but rather provide a secondary check to ensure all data has been synchronized. Normally, all data will be sent via points as it is changes and if all points are received, the Hash is not needed. Therefore, we want to prioritize performance and efficiency over hash strength. The XOR function has some interesting properties:
- Commutative: A ⊕ B = B ⊕ A (the ability to process elements in any order and get the same answer)
- Associative: A ⊕ (B ⊕ C) = (A ⊕ B) ⊕ C (we can group operations in any order)
- Identity: A ⊕ 0 = A
- Self-Inverse: A ⊕ A = 0 (we can back out an input value by simply applying it again)
See hash_test.go for tests of the XOR concept.
Point CRC
Point CRCs are calculated using the CRC-32 of the following point fields:
TimeTypeKeyTextValue
Updating the Node Hash
- Edge or node points received
- For points updated
- Back out previous point CRC
- Add in new point CRC
- Update upstream hash values (stops at device node)
- Create cache of all upstream edges to root
- For each upstream edge, back out old hash, and xor in new hash
- Write all updated edge hash fields
- For points updated
It should again be emphasized that repetitive or high rate points should not be included in the hash because they will be sent again soon - we do not need the hash to ensure they get synchronized. The hash should only include points that change at slow rates (user changes, state, etc.). Anything machine generated should be repeated - even if only every 10 minutes.
The hash is only useful in synchronizing state between a device node tree, and a subset of the upstream node tree. For instances which do not have an upstream of peer instances, there is little value in calculating hash values back to the root node and could be computationally intensive for a cloud instance that had 1000’s of child nodes.
Reliability
Reliability is an important consideration in any IoT system as these systems are often used to monitor and control critical systems and processes. Performance is a key aspect of reliability because if the system is not performing well, then it can’t keep up and do its job.
Point Metrics
The fundamental operation of SimpleIoT is that it process points, which are
changes to nodes. If the system can’t process points at the rate they are
coming in, then we have a problem as data will start to back up and the system
will not be responsive.
Points and other data flow through the NATS messaging system, therefore it is perhaps the first place to look. We track several metrics that are written to the root device node to help track how the system is performing.
The NATS client buffers messages that are received for each subscription and
then messages are
dispatched serially one message at a time.
If the application can’t keep up with processing messages, then the number of
buffered messages increases. This number is occasionally read and then
min/max/avg written to the metricNatsPending* points in the root device
node.
The time required to process points is tracked in the metricNatsCycle* points
in the root device node. The cycle time is in milliseconds.
We also track point throughput (messages/sec) for various NATS subjects in the
metricNatsThroughput* points.
These metrics should be graphed and notifications sent when they are out of the normal range. Rules that trigger on the point type can be installed high in the tree above a group of devices so you don’t have to write rules for every device.
Database interactions
Database operations greatly affect system performance. When Points come into the system, we need to store this data in the primary and time series stores (ex InfluxDB). The time it takes to read and write data greatly impacts how much data we can handle.
IO failures
All errors reading/writing IO devices should be tracked at both the device and bus level. These can be observed over time and abnormal rates can trigger notifications. Error counts should be reported at a low rate to avoid using bandwidth and resources - especially if multiple counts are incremented on an error (IO and bus).
Logging
Many errors are currently reported as log messages. Eventually some effort should be made to turn these into error counts and possibly store them in the time series store for later analysis.
API
Contents
The Simple IoT server currently provides both HTTP and NATS.io APIs. We’ve tried to keep the two APIs a similar as possible so it is easy to switch from one to the other. The HTTP API currently accepts JSON, and the NATS API uses Protobuf.
NOTE, the Simple IoT API is not final and will continue to be refined in the coming months.
NATS
NATS.io allows more complex and efficient interactions between various system components (device, cloud, and web UI). These three parts of the system make IoT systems inherently distributed. NATS focuses on simplicity and is written in Go which ensures the Go client is a 1st class citizen and allows for interesting possibilities such as embedding in the NATS server in various parts of the system. This allows us to keep our one-binary deployment model.
The siot binary embeds the NATS server, so there is no need to deploy and run
a separate NATS server.
For the NATS transport, Protobuf encoding is used for all transfers and are defined here.
- Nodes
nodes.<parentId>.<nodeId>- Request/response - returns an array of
data.EdgeNodestructs. parent="all", then all instances of the node are returned.parent is set and id="all", then all child nodes of the parent are returned.parent="root" and id="all"to fetch the root node(s).- The following combinations are invalid:
parent="all" && id="all"
- Parameters can be specified as points in payload
tombstonewith value field set to 1 will include deleted pointsnodeTypewith text field set to node type will limit returned nodes to this type
- Request/response - returns an array of
p.<nodeId>- Used to listen for or publish node point changes.
p.<nodeId>.<parentId>- Used to publish/subscribe node edge points. The
tombstonepoint type is used to track if a node has been deleted or not.
- Used to publish/subscribe node edge points. The
phr.<nodeId>(not currently used)- high rate point data
phrup.<upstreamId>.<nodeId>- High rate point data is rebroadcast upstream.
upstreamIdis the parent of the node that is interested in HR data (currently the db node).nodeIdis the node that is providing the HR data. In the case of a custom HRDest Node(serial client), the serial client may not be a child of the upstream node.
- High rate point data is rebroadcast upstream.
up.<upstreamId>.<nodeId>- Node points are rebroadcast at every upstream ID so that we can listen for
point changes at any level. The sending node is also included in this. The
store is responsible for posting to
upsubjects. Individual clients should not do this.
- Node points are rebroadcast at every upstream ID so that we can listen for
point changes at any level. The sending node is also included in this. The
store is responsible for posting to
up.<upstreamId>.<nodeId>.<parentId>- Edge points rebroadcast at every upstream node ID.
history.<nodeId>- Request/response - payload is a JSON-encoded
HistoryQuerystruct. Returns a JSON-encodeddata.HistoryResult.
- Request/response - payload is a JSON-encoded
- Legacy APIs that are being deprecated
node.<id>.not- Used when a node sends a notification (typically a rule, or a message sent directly from a node)
node.<id>.msg- Used when a node sends a message (SMS, email, phone call, etc.). This is typically initiated by a notification.
node.<id>.file(not currently implemented)- Is used to transfer files to a node in chunks, which is optimized for unreliable networks like cellular and is handy for transferring software update files.
- Auth
auth.user- Used to authenticate a user. Send a request with email/password points, and the system will respond with the User nodes if valid. There may be multiple user nodes if the user is instantiated in multiple places in the node graph. A JWT node will also be returned with a token point. This JWT should be used to authenticate future requests. The frontend can then fetch the parent node for each user node.
auth.getNatsURI- This returns the NATS URI and Auth Token as points. This is used in cases where the client needs to set up a new connection to specify the no-echo option, or other features.
- Admin
admin.error(not implemented yet)- Any errors that occur are sent to this subject
admin.storeVerify- Used to initiate a database verification process. This currently verifies hash values are correct and responds with an error string.
admin.storeMaint- Corrects errors in the store (current incorrect hash values)
HTTP
For details on data payloads, it is simplest to just refer to the Go types which have JSON tags.
Most APIs that do not return specific data (update/delete) return a standard response
- Nodes
- data structure
/v1/nodes- GET: return a list of all nodes
- POST: insert a new node
/v1/nodes/:id- GET: return info about a specific node. Body can optionally include the id of parent node to include edge point information.
- DELETE: delete a node
/v1/nodes/:id/parents- POST: move node to new parent
- PUT: mirror/duplicate node
- body is JSON
api/nodes.go:NodeMoveorNodeCopystructs
/v1/nodes/:id/points- POST: post points for a node
/v1/nodes/:id/cmd- GET: gets a command for a node and clears it from the queue. Also clears
the
CmdPendingflag in the Device state. - POST: posts a
cmdfor the node and sets the nodeCmdPendingflag.
- GET: gets a command for a node and clears it from the queue. Also clears
the
/v1/nodes/:id/not- POST: send a notification to all node users and upstream users
- Auth
/v1/auth- POST: accepts
emailandpasswordas form values, and returns a JWT Auth token
- POST: accepts
HTTP Examples
You can post a point using the HTTP API without authorization using curl:
curl -i -H "Content-Type: application/json" -H "Accept: application/json" -X POST -d '[{"type":"value", "value":100}]' http://localhost:8118/v1/nodes/be183c80-6bac-41bc-845b-45fa0b1c7766/points
If you want HTTP authorization, set the SIOT_AUTH_TOKEN environment variable
before starting Simple IoT and then pass the token in the authorization header:
curl -i -H "Authorization: f3084462-3fd3-4587-a82b-f73b859c03f9" -H "Content-Type: application/json" -H "Accept: application/json" -X POST -d '[{"type":"value", "value":100}]' http://localhost:8118/v1/nodes/be183c80-6bac-41bc-845b-45fa0b1c7766/points
Frontend
Elm Reference Implementation
The reference Simple IoT frontend is implemented in Elm as a Single Page
Application (SPA) and is located in the
frontend/
directory.
Code Structure
The frontend is based on elm-spa, and is split into the following directories:
Api: contains core data structures and API code to communicate with backend (currently REST).Pages: the various pages of the applicationComponents: each node type has a separate module that is used to render it.NodeOptions.elmcontains a struct that is used to pass options into the component views.UI: Various UI pieces we usedUtils: Code that does not fit anywhere else (time, etc.)
We’d like to keep the UI optimistic if possible.
Creating Custom Icons
SIOT icons are 24x24px pixels (based on feather icon format). One way to
create them is to:
- Create a
24x24pxdrawing in Inkscape, scale=1.0 - draw your icon
- if you use text
- Convert text to path: select text, and then menu Path -> Object to Path
- Make sure fill is set for path
- save as plain SVG
- set up a new Icon in
frontend/src/UI/Icon.elmand use an existing custom icon likevariableas a template. - Copy the SVG path strings from the SVG file into the new Icon
- You’ll likely need to adjust the scaling transform numbers to get the icon to the right size
(I’ve tried using: https://levelteams.com/svg-to-elm, but this has not been real useful, so I usually end up just copying the path strings into an elm template and hand edit the rest)
File upload
The File node UI has the capability to upload files in the browser and then store them in a node point. The default max payload of NATS is 1MB, so that is currently the file size limit, but NATS can be configured for a payload size up to 64MB. 8MB is recommended.
Currently the payload is stored in the Point String field for simplicity. If
the binary option is selected, the data is base64 encoded. Long term it may make
sense to support JetStream Object store, local file store, etc.
The elm/file package is used upload a file into the browser. Once the data is in the browser, it is sent to the backup as a standard point payload. Because we are currently using a JSON API, binary data is base64 encoded.
The process by which a file is uploaded is:
- The
NodeOptionsstruct, which is passed to all nodes has anonUploadFilefield, which is used to triggers theUploadFilemessage which runs a browser file select. The result of this select is aUploadSelectedmessage. - This message calls
UploadFile node.node.idinHome_.elm. File.Select.fileis called to select the file, which triggers theUploadContentsmessage.UploadContentsis called with the node id, file name, and file contents, which then sends the data via points to the backend.
SIOT JavaScript library using NATS over WebSockets
This is a JavaScript library available in the
frontend/lib
directory that can be used to interface a frontend with the SIOT backend.
Usage:
import { connect } from "./lib/nats"
async function connectAndGetNodes() {
const conn = await connect()
const [root] = await conn.getNode("root")
const children = await conn.getNodeChildren(root.id, { recursive: "flat" })
return [root].concat(children)
}
This library is also published on NPM (in the near future).
(see #357)
(Note, we are not currently using this yet in the SIOT frontend we still poll the backend over REST and fetch the entire node tree, but we are building out infrastructure so we don’t have to do this.)
Custom UIs
The current SIOT UI is more an engineering type view than something that might be used by end users. For a custom/company product IoT portal where you want a custom web UI optimized for your products, there are several options:
- Modify the existing SIOT frontend.
- Write a new frontend, mobile app, desktop app, etc. The SIOT backend and frontend are decoupled so that this is possible.
Passing a custom UI to SIOT
There are ways to use a custom UI with SIOT at the app and package level:
- Application: pass a directory containing your public web assets to the
app using:
siot serve -customUIDir <your web assets> - Package: populate
CustomUIFSwith afs.FSin the SIOT server options`.
In both cases, the filesystem should contain a index.html in the root
directory. If it does not, you can use the
fs.Sub function to return a subtree of a
fs.FS.
Rules
Rules are defined by nodes and are composed of additional child nodes for conditions and actions. See the node/point schema for more details.
All points should be sent out periodically, even if values are not changing to indicate a node is still alive and eliminate the need to periodically run rules. Even things like system state should be sent out to trigger device/node offline notifications.
Notifications
(see notification user documentation
Notifications are messages that are sent to users. There several concerns when processing a notification:
- The message itself and how it is generated.
- Who receives the messages.
- Mechanism for sending the message (Twilio SMS, SMTP, etc.)
- State of the notification
- Sequencing through a list of users
- Tracking if it was acknowledged and by who
- Distributed concerns (more than one SIOT instance processing notifications)
- Synchronization of notification state between instances.
- Which instance is processing the notification.
For now, we assume all notifications will be handled on a single SIOT instance (typically in the cloud) - distributed aspects of notifications will implemented later.
Notifications can be initiated by:
- Rules
- Users sending notifications through the web UI
Notification Data Structures
Elsewhere in the system, configuration and sensor data are represented as Points. The Point data structure is optimized for synchronization and algorithms where simplicity and consistency allows us to easily process points with common code. But a Point does not have enough fields to represent a message or notification. We could encode the message as JSON in the Point text field, but it would be nice to have something a little more descriptive. Additionally, all notifications and messages should be stored in the time series database so there is a history of everything that was sent.
Time series databases like InfluxDB store records with the following attributes:
- Timestamp
- Measurement (similar to collection, bucket, or table in other databases)
- Keys (string only, indexed)
- Values (can be a variety of data types: float, integer, string, boolean)
Notifications will be handled by two data structures:
- Notification
- Typically generated by a rule or a node that is directly sending a message
- Stored in main database as they may contain state that needs to be processed over time
- Message
- An individual message to a user (SMS, Email, voice call)
- Stored in time series database as they are transient
Notifications are initiated (as is all write data in the system) by sending a message through NATS. The typical flow is as follows:
Rule -> Notification -> Message
Integration
This page discusses ways you can integration Simple IoT into your system. At its core, SIOT is a distributed graph database optimized for storing, viewing, and synchronizing state/config in IoT systems. This makes it very useful for any system where you need distributed state/config.
With SIOT, you run the same application in both the cloud and edge devices, so you can use any of the available integration points at either place.
The SIOT API
This primary way to interact with Simple IoT is through a NATS API. You can add additional processes written in any language that has a NATS client. Additionally, the NATS wire protocol is fairly simple so could be implemented from scratch if needed. If your most of your system is written in C++, but you needed a distributed config/state store, then run SIOT along side your existing processes and add a NATS connection to SIOT. If you want easy scripting in your system, consider writing a Python application that can read/modify the SIOT store over NATS.
SIOT Data Structures
The SIOT data structures are very general (nodes and points) arranged in a graph, so you can easily add your own data to the SIOT store by defining new node and point types as needed. This makes SIOT very flexible and adaptable to about any purpose. You can use points in a node to represent maps and arrays. If your data needs more structure, then nested nodes can accomplish that. It is important with SIOT data to retain CRDT properties. These concepts are discussed more in ADR-1.
The requirement to only use nodes and points may seem restrictive at first, but can be viewed as a serialization format with CRDT properties that are convenient for synchronization. Any distributed database requires meta data around your data to assist with synchronization. With SIOT, we have chosen to make this metadata simple and accessible to the user. It is typical to convert this data to more convenient data structures in your application - much the same way you would deserialize JSON.
The architecture page discusses data structures in more detail.
Time series data and Graphing
If you need history and graphs, you can add InfluxDB and Grafana. This instantly provides history and graphs of all state and configuration changes that happened in the system.
Embedded Linux Systems
Simple IoT was designed with Embedded Linux systems in mind, so it is very efficient - a single, statically linked Go binary with all assets embedded that is ~20MB in size and uses ~20MB of memory. There are no other dependencies required such as a runtime, other libraries, etc. This makes SIOT extremely easy to deploy and update. An Embedded Linux system deployed at the edge can be synchronized with a cloud instance using a sync connection.
Integration with MCU (Microcontroller) systems
MCUs are processors designed for embedded control and are typically 32-bit CPUs that run bare-metal code or a small OS like FreeRTOS or Zephyr and don’t have as much memory as MPUs. MCUs cannot run the full SIOT application or easily implement a full data-centric data store. However, you can still leverage the SIOT system by using the node/point data structures to describe configuration and state and interacting with a Simple IoT like any other NATS client. Nanopb can be used on MCUs to encode and decode Protobuf messages, which is the default encoding for SIOT messages.
If your MCU supports MQTT, then it may make sense to use that to interact with Simple IoT as MQTT is very similar to NATS, and NATS includes a built-in MQTT server. The NATS wire protocol is also fairly simple and can also be implemented on top of any TCP/IP stack.
If your MCU interfaces with a local SIOT system using USB, serial, or CAN, then you can use the SIOT serial adapter.
Serial Devices
Contents
(see also user documentation and SIOT Firmware)
It is common in embedded systems architectures for an MPU (Linux-based running SIOT) to be connected via a serial link (RS232, RS485, CAN, USB serial) to an MCU.
See this article for a discussion on the differences between an MPU and MCU. These devices are not connected via a network interface, so can’t use the SIOT NATS API directly, thus we need to define a proxy between the serial interface and NATS for the MCU to interact with the SIOT system.
State/config data in both the MCU and MPU systems are represented as nodes and points. An example of nodes and points is shown below. These can be arranged in any structure that makes sense and is convenient. Simple devices may only have a single node with a handful of points.
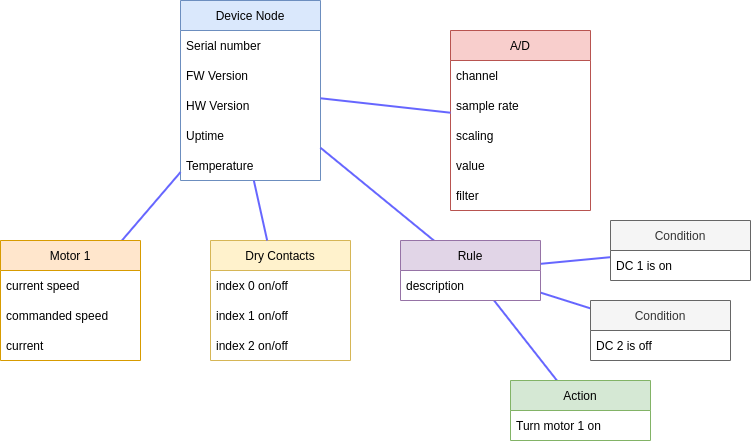
SIOT does not differentiate between state (ex: sensor values) and config (ex: pump turn-on delay) - it is all points. This simplifies the transport and allows changes to be made in multiple places. It also allows for the granular transmission and synchronization of data - we don’t need to send the entire state/config anytime something changes.
SIOT has the ability to log points to InfluxDB, so this mechanism can also be used to log messages, events, state changes, whatever - simply use an existing point type or define a new one, and send it upstream.
Data Synchronization
By default, the serial client synchronizes any extra points written to the serial node. The serial UI displays the extra points as shown below:
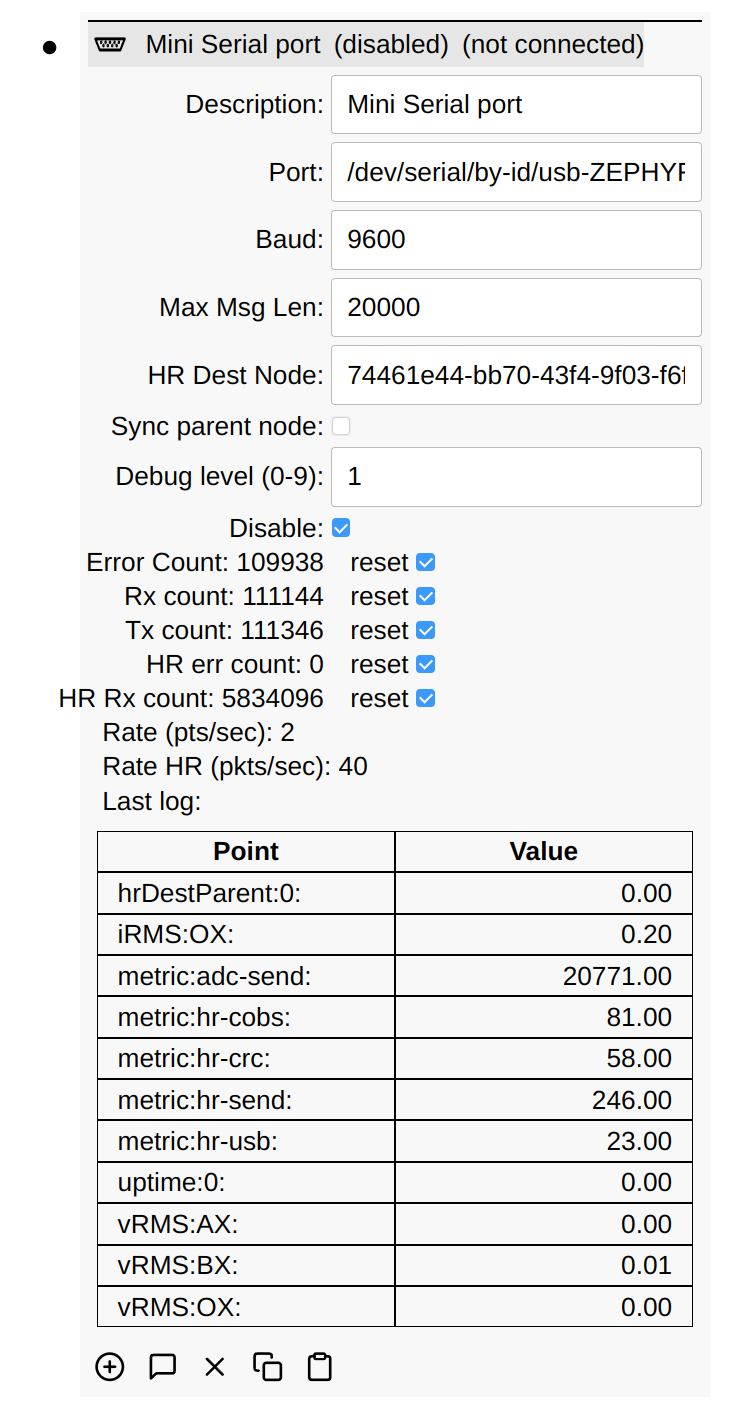
Alternatively, there is an option for the serial client to sync its parent’s points to the serial device. When this is selected, any points received from the serial device are posted to the parent node, and any points posted to the parent node that were not sent by the serial device are forwarded to the serial client.
Protocol
The SIOT serial protocol mirrors the NATS PUB message with a few assumptions:
- We don’t have mirrored nodes inside the MCU device
- The number of nodes and points in an MCU is relatively small
- The payload is always an array of points
- Only the following SIOT NATS API subjects are supported:
- Blank (assumes ID of Serial MCU client node
p.<id>(used to send node points)p.<id>.<parent>(used to send edge points)phr(specifies high-rate payload)
- We don’t support NATS subscriptions or requests - on startup, we send the entire dataset for the MCU device in both directions (see On connection section), merge the contents, and then assume any changes will get sent and received after that.
subject can be left blank when sending/receiving points for the MCU root node.
This saves some data in the serial messages.
The point type nodeType is used to create new nodes and to send the node type
on connection.
All packets are ack’d (in both directions) by an empty packet with the same sequence number and subject set to ‘ack’. If an ack is not received in X amount of time, the packet is retried up to 3 times, and then the other device is considered “offline”.
Encoding
Packet Frame
All packets between the SIOT and serial MCU systems are framed as follows:
sequence (1 byte, rolls over)
subject (16 bytes)
payload (Protobuf Point array or HR repeated point payload)
crc (2 bytes) (Currently using CRC-16/KERMIT) (not included on log messages)
Protocols like RS232 and USB serial do not have any inherent framing; therefore, this needs to be done at the application level. SIOT encodes each packet using COBS (Consistent Overhead Byte Stuffing).
Log payload
The log message is specified with log in the packet frame subject. The payload
is ASCII characters and CRC not included.
Protobuf payload
The serial Protobuf type is used to transfer these messages:
message SerialPoint {
string type = 2;
float value = 4;
int64 time = 16;
float index = 13;
string text = 8;
string key = 11;
int32 tombstone = 12;
}
Protobuf can be used for low-rate samples, config, state, etc.
Protobuf is used to encode the data on the wire. Find Protobuf files here. Nanopb can be used to generate C-based Protobuf bindings that are suitable for use in most MCU environments.
High-rate payload
A simple payload encoding for high-rate data can be used to avoid the overhead
of Protobuf encoding and is specified with phr in the packet frame subject.
type (16 bytes) point type
key (16 bytes) point key
starttime (uint64) starting time of samples in ns since Unix Epoch
sampleperiod (uint32) time between samples in ns
data (variable, remainder of packet), packed 32-bit floating point samples
This data bypasses most of the processing in SIOT and is sent to a special
phr NATS subject. Clients that are interested in high-rate data
(like the InfluxDB client) can listen to these subjects.
File payload
This payload type is for transferring files in blocks. These files may be used for firmware updates or other transfers where large amounts of data need to be transferred. An empty block with index set to -1 is sent at the end of the transfer.
name (16 bytes) filename
index (4 bytes) file block index
data (variable, remainder of packet)
On connection
On initial connection between a serial device and SIOT, the following steps are done:
- The MCU sends the SIOT system an empty packet with its root node ID
- The SIOT systems sends the current time to the MCU (point type
currentTime) - The MCU updates any “offline” points with the current time (see offline section).
- The SIOT acks the current time packet.
- All the node and edge points are sent from the SIOT system to the MCU, and
from the MCU to the SIOT system. Each system compares point time stamps and
updates any points that are newer. Relationships between nodes are defined by
edge points (point type
tombstone).
Timestamps
The Simple IoT uses a 64-bit nanosecond since Unit epoch value for all timestamps.
Fault handling
Any communication medium has the potential to be disrupted (unplugged/damaged wires, one side off, etc.). Devices should continue to operate and when re-connected, do the right thing.
If an MCU has a valid time (RTC, sync from SIOT, etc.), it will continue operating, and when reconnected, it will send all its points to re-sync.
If an MCU powers up and has no time, it will set the time to 1970 and start operating. When it receives a valid time from the SIOT system, it will compute the time offset from the SIOT time and its own 1970 based time. It then indexes through all points and adds the offset to any points with time less than 2020, and then send all points to SIOT.
When the MCU syncs time with SIOT, if the MCU time is ahead of the SIOT system, then it set its time, and look for any points with a time after present, and reset these timestamps to the present.
RS485
Status: Idea
RS485 is a half duplex, prompt response transport. SIOT periodically prompts MCU devices for new data at some configurable rate. Data is still COBS encoded so that is simple to tell where packets start/stop without needing to rely on dead space on the line.
Simple IoT also supports Modbus, but the native SIOT protocol is more capable - especially for structured data.
Addressing: TODO
CAN
Status: Idea
CAN messages are limited to 8 bytes. The J1939 Transport Protocol can be used to assemble multiple messages into a larger packet for transferring up to 1785 bytes.
Implementation notes
Both the SIOT and MCU side need to store the common set of nodes and points
between the systems. This is critical as the point merge algorithm only uses an
incoming point if the incoming point is newer than the one currently stored on
the device. For SIOT NATS clients, we use the NodeEdge data structure:
type NodeEdge struct {
ID string
Type string
Parent string
Points Points
EdgePoints Points
Origin string
}
Something similar could be done on the MCU.
If new nodes are created on the MCU, the ID must be an UUID, so that it does not conflict with any of the node IDs in the upstream SIOT system(s).
On the SIOT side, we keep a list of Nodes on the MCU and periodically check if any new Nodes have been created. If so, we send the new Nodes to the MCU. Subscriptions are set up for points and edges of all nodes, and any new points are sent to the MCU. Any points received from the MCU simply forwarded to the SIOT NATS bus.
DFU
Status: Idea
For devices that support USB Device Firmware Upgrade (DFU), SIOT provides a mechanism to do these updates. A node that specifies USB ID and file configures the process.
Version
The Simple IoT app stores and uses three different version values:
- App Version
- OS Version
- HW Version
The App version is compiled into the application Go binary by the build (see the
envsetup.sh
file). This version is based on the latest Git tag plus hash if there have been
any changes since the tag.
On Linux, the OS version is extracted from the VERSION field in
/etc/os-release. The field can be changed using
the OS_VERSION_FIELD environment variable.
The versions are displayed in the root node as shown below:
Security
Users and downstream devices will need access to a Simple IoT instance. Simple IoT currently provides access via HTTP and NATS.
Server
For cloud/server deployments, we recommend installing a web server like Caddy in front of Simple IoT. See the Installation page for more information.
Edge
Simple IoT Edge instances initiate all connections to upstream instances; therefore, no incoming connections are required on edge instances and all incoming ports can be firewalled.
HTTP
The Web UI uses JWT (JSON web tokens).
Devices can also communicate via HTTP and use a simple auth token. Eventually may want to switch to JWT or something similar to what NATS uses.
NOTE, it is important to set an auth token - otherwise there is no restriction on accessing the device API.
NATS
Currently devices communicating via NATS use a common auth token. It would be nice to move to something where each device has its own authentication (TODO, explore NATS advanced auth options).
Long term we plan to leverage the NATS security model for user and device authn/authz.:
Research
This document contains information that has been researched during the course of creating Simple IoT.
Synchronization
An IoT system is inherently distributed. At a minimum, there are three components:
- Device (Go, C, etc.)
- Cloud (Go)
- Multiple browsers (Elm, JavaScript)
Data can be changed in any of the above locations and must be seamlessly synchronized to other locations. Failing to consider this simple requirement early in building the system can make for brittle and overly complex systems.
The moving target problem
As long as the connection between instances is solid, they will stay synchronized as each instance will receive all points it is interested in. Therefore, verifying synchronization by comparing Node hashes is a backup mechanism - that allows us to see what changed when disconnected. The root hashes for a downstream instance changes every time anything in that system changes. Only one value needs to be compared to ensure your entire config is synchronized, but it is also a disadvantage in that the top level hash is changing more often so you are trying to compare two moving targets. This is not a problem if things are changing slow enough that it does not matter if they are changing. However, this also limits the data rates to which we can scale.
Some systems use a concept called Merkle clocks, where events are stored in a Merle DAG and existing nodes in the DAG are immutable and new events are always added as parents to existing events. An immutable DAG has an advantage in that you can always work back in history, which never changes. The SIOT Node tree is mutable by definition. Actual budget uses a similar concept in that it uses a Merkle Trie to represent events in time and then prunes the tree as time goes on.
We could create a separate structure to sync all events (points), but that would require a separate structure on the server for every downstream device and seems overly complex.
Is it critical that we see all historical data? In an IoT system, there are essentially two sets of date - current state/config, and historical data. The current state is most critical for most things, but historical data may be used for some algorithms and viewed by users. The volume of data makes it impractical to store all data in resource constrained edge systems. However, maybe it’s a mistake to separate these two as synchronizing all data might simplify the system.
One way to handle the moving target problem is to store an array of previous hashes for the device node in both instances - perhaps for as long as the synchronization interval. The downstream could then fetch the upstream hash array and see if any of the entries match an entry in the downstream array. This would help cover the case where there may be some time difference when things get updated, but the history should be similar. If there is a hash in history that matches, then we are probably OK.
Another approach would be to track metrics on how often the top level hash is updating - if it is too often, then perhaps the system needs tuned.
There could also be some type of stop-the-world lock where both systems stop processing new nodes during the sync operation. However, if they are not in sync, this probably won’t help and definitely hurts scalability.
Resgate
resgate.io is an interesting project that solves the problem of creating a real-time API gateway where web clients are synchronized seamlessly. This project uses NATS.io for a backbone, which makes it interesting as NATS is core to this project.
The Resgate system is primarily concerned with synchronizing browser contents.
Couch/pouchdb
Has some interesting ideas.
Merkle Trees
- https://en.wikipedia.org/wiki/Merkle_tree
- https://jack-vanlightly.com/blog/2016/10/24/exploring-the-use-of-hash-trees-for-data-synchronization-part-1
- https://www.codementor.io/blog/merkle-trees-5h9arzd3n8
- Version Control Systems Version control systems like Git and Mercurial use specialized Merkle trees to manage versions of files and even directories. One advantage of using Merkle trees in version control systems is we can simply compare hashes of files and directories between two commits to know if they’ve been modified or not, which is quite fast.
- No-SQL distributed database systems like Apache Cassandra and Amazon DynamoDB use Merkle trees to detect inconsistencies between data replicas. This process of repairing the data by comparing all replicas and updating each one of them to the newest version is also called anti-entropy repair. The process is also described in Cassandra’s documentation.
Scaling Merkel trees
One limitation of Merkel trees is the difficulty of updating the tree concurrently. Some information on this:
Distributed key/value databases
- etcd
- NATS key/value store
Distributed Hash Tables
- https://en.wikipedia.org/wiki/Distributed_hash_table
CRDT (Conflict-free replicated datatype)
- https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type
- Yjs
- https://blog.kevinjahns.de/are-crdts-suitable-for-shared-editing/
- https://tantaman.com/2022-10-18-lamport-sufficient-for-lww.html
Databases
- https://tantaman.com/2022-08-23-why-sqlite-why-now.html
- instead of doing:
select comment.* from post join comment on comment.post_id = post.id where post.id = x and comment.date < cursor.date and comment.id < cursor.id order by date, id desc limit 101 - we do:
post.comments().last(10).after(curosr);
- instead of doing:
Timestamps
- Lamport timestamp
- used by Yjs
Other IoT Systems
AWS IoT
- https://www.thingrex.com/aws_iot_thing_attributes_intro/
- Thing properties include the following, which are analogous to SIOT node
fields.
- Name (Description)
- Type (Type)
- Attributes (Points)
- Groups (Described by tree structure)
- Billing Group (Can also be described by tree structure)
- Thing properties include the following, which are analogous to SIOT node
fields.
- https://www.thingrex.com/aws_iot_thing_type/
- Each type has a specified attributes - kind of a neat idea
Architecture Decision Records
This directory is used to capture Simple IoT architecture and design decisions.
For background on ADRs see Documenting Architecture Decisions by Michael Nygard. Also see an example of them being used in the NATS project. The Go proposal process is also a good reference.
Process
When thinking about architectural changes, we should lead with documentation. This means we should start a branch, draft a ADR, and then open a PR. An associated issue may also be created.
ADRs should used primarily when a number of approaches need to be considered, thought through, and we need a record of how and why the decision was made. If the task is a fairly straightforward implementation, write documentation in the existing User and Reference Guide sections.
When an ADR is accepted and implemented, a summary should typically be added to the Reference Guide documentation.
See template.md for a template to get started.
ADRs
| Index | Description |
|---|---|
| ADR-1 | Consider changing/expanding point data type |
| ADR-2 | Authorization considerations. |
| ADR-3 | Node lifecycle |
| ADR-4 | Notes on storing and transferring time |
| ADR-5 | How do we ensure we have valid time |
| ADR-6 | How to handle time in rule schedules |
| ADR-7 | Use NATS Jetstream for the SIOT store |
Point Data Type Changes
- Author: Cliff Brake Last updated: 2023-06-13
- Issue at: https://github.com/simpleiot/simpleiot/issues/254
- PR/Discussion:
- https://github.com/simpleiot/simpleiot/pull/279
- https://github.com/simpleiot/simpleiot/pull/565
- https://github.com/simpleiot/simpleiot/pull/566
- Status: Review
Contents
Problem
The current point data type is fairly simple and has proven useful and flexible to date, but we may benefit from additional or changed fields to support more scenarios. It seems in any data store, we need at the node level to be able to easily represent:
- arrays
- maps
IoT systems are distributed systems that evolve over time. If can’t easily handle schema changes and synchronize data between systems, we don’t have anything.
Context/Discussion
Should we consider making the point struct more flexible?
The reason for this is that it is sometimes hard to describe a sensor/configuration value with just a few fields.
Requirements
- IoT systems are often connected by unreliable networks (cellular, etc). All devices/instances in a SIOT should be able to functional autonomously (run rules, etc) and then synchronize again when connected.
- all systems must converge to the same configuration state. We can probably tolerate some lost time series data, but configuration and current state must converge. When someone is remotely looking at a device state, we want to make sure they are seeing the same things a local operator is seeing.
evolvability
From Martin Kleppmann’s book:
In a database, the process that writes to the database encodes the data, and the process that reads from the database decodes it. There may just be a single process accessing the database, in which case the reader is simply a later version of the same process—in that case you can think of storing something in the database as sending a message to your future self.
Backward compatibility is clearly necessary here; otherwise your future self won’t be able to decode what you previously wrote.
In general, it’s common for several different processes to be accessing a database at the same time. Those processes might be several different applications or services, or they may simply be several instances of the same service (running in parallel for scalability or fault tolerance). Either way, in an environment where the application is changing, it is likely that some processes accessing the database will be running newer code and some will be running older code—for example because a new version is currently being deployed in a rolling upgrade, so some instances have been updated while others haven’t yet.
This means that a value in the database may be written by a newer version of the code, and subsequently read by an older version of the code that is still running. Thus, forward compatibility is also often required for databases.
However, there is an additional snag. Say you add a field to a record schema, and the newer code writes a value for that new field to the database. Subsequently, an older version of the code (which doesn’t yet know about the new field) reads the record, updates it, and writes it back. In this situation, the desirable behavior is usually for the old code to keep the new field intact, even though it couldn’t be interpreted.
The encoding formats discussed previously support such preservation of unknown fields, but sometimes you need to take care at an application level, as illustrated in Figure 4-7. For example, if you decode a database value into model objects in the application, and later re-encode those model objects, the unknown field might be lost in that translation process. Solving this is not a hard problem; you just need to be aware of it.
Some discussion of this book: https://community.tmpdir.org/t/book-review-designing-data-intensive-applications/288/6
CRDTs
Some good talks/discussions:
I also agree CRDTs are the future, but not for any reason as specific as the ones in the article. Distributed state is so fundamentally complex that I think we actually need CRDTs (or something like them) to reason about it effectively. And certainly to build reliable systems. The abstraction of a single, global, logical truth is so nice and tidy and appealing, but it becomes so leaky that I think all successful systems for distributed state will abandon it beyond a certain scale. – Peter Bourgon
CRDTs, the hard parts by Martin Kleppmann
Infinite Parallel Universes: State at the Edge
Properties of CRDTs:
- Associative (order in which operations are performed does matter)
- Commutative (changing order of operands does not change result)
- Idempotent (operation can be applied multiple times without changing the result, tolerate over-merging)
The existing SIOT Node/Point data structures were created before I know what a CRDT was, but they happen to already give a node many of the properties of a CRDT – IE, they can be modified independently, and then later merged with a reasonable level of conflict resolution.
For reliable data synchronization in distributed systems, there has to be some metadata around data that facilitates synchronization. This can be done in two ways:
- add meta data in parallel to the data (turn JSON into a CRDT, example automerge or yjs)
- express all data using simple primitives that facilitate synchronization
Either way, you have to accept constraints in your data storage and transmission formats.
To date, we have chosen to follow the 2nd path (simple data primitives).
Operational transforms
There are two fundamental schools of thought regarding data synchronization:
- Operation transforms. In this method, a central server arbitrates all conflicts and hands the result back to other instances. This is an older technique and is used in applications like Google docs.
- CRDTs – this is a newer technique that works with multiple network connections and does not require a central server. Each instance is capable of resolving conflicts themselves and converging to the same point.
While a classical OT arrangement could probably work in a traditional SIOT system (where all devices talk to one cloud server), it would be nice if we are not constrained to this architecture. This would allow us to support peer synchronization in the future.
Other Standards
Some reference/discussion on other standards:
Sparkplug
https://github.com/eclipse/tahu/blob/master/sparkplug_b/sparkplug_b.proto
The sparkplug data type is huge and could be used to describe very complex data. This standard came out of the industry 4.0 movement where a factory revolves around a common MQTT messaging server. The assumption is that everything is always connected to the MQTT server. However, with complex types, there is no provision for intelligent synchronization if one system is disconnected for some amount of time – its all or nothing, thus it does not seem like a good fit for SIOT.
SenML
https://datatracker.ietf.org/doc/html/draft-ietf-core-senml-08#page-9
tstorage
The tstorage Go package has an interesting data storage type:
type Row struct {
// The unique name of metric.
// This field must be set.
Metric string
// An optional key-value properties to further detailed identification.
Labels []Label
// This field must be set.
DataPoint
}
type DataPoint struct {
// The actual value. This field must be set.
Value float64
// Unix timestamp.
Timestamp int64
}
type Label struct {
Name string
Value string
In this case there is one value and an array of labels, which are essentially key/value strings.
InfluxDB
InfluxDB’s line protocol contains the following:
type Metric interface {
Time() time.Time
Name() string
TagList() []*Tag
FieldList() []*Field
}
type Tag struct {
Key string
Value string
}
type Field struct {
Key string
Value interface{}
}
where the Field.Value must contain one of the InfluxDB supported types (bool, uint, int, float, time, duration, string, or bytes).
time-series storage considerations
Is it necessary to have all values in one point, so they can be grouped as one entry in a time series data base like influxdb? Influx has a concept of tags and fields, and you can have as many as you want for each sample. Tags must be strings and are indexed and should be low cardinality. Fields can be any datatype influxdb supports. This is a very simple, efficient, and flexible data structure.
Example: location data
One system we are working with has extensive location information (City/State/Facility/Floor/Room/Isle) with each point. This is all stored in influx so we can easily query information for any location in the past. With SIOT, we could not currently store this information with each value point, but would rather store location information with the node as separate points. One concern is if the device would change location. However, if location is stored in points, then we will have a history of all location changes of the device. To query values for a location, we could run a two pass algorithm:
- query history and find time windows when devices are in a particular location.
- query these time ranges and devices for values
This has the advantage that we don’t need to store location data with every point, but we still have a clear history of what data come from where.
Example: file system metrics
When adding metrics, we end up with data like the following for disks partitions:
Filesystem Size Used Avail Use% Mounted on
tmpfs 16806068224 0 16806068224 0% /dev
tmpfs 16813735936 1519616 16812216320 0% /run
ext2/ext3 2953064402944 1948218814464 854814945280 70% /
tmpfs 16813735936 175980544 16637755392 1% /dev/shm
tmpfs 16813740032 3108966400 13704773632 18% /tmp
ext2/ext3 368837799936 156350181376 193680359424 45% /old3
msdos 313942016 60329984 253612032 19% /boot
ext2/ext3 3561716731904 2638277668864 742441906176 78% /scratch
tmpfs 3362746368 118784 3362627584 0% /run/user/1000
ext2/ext3 1968874332160 418203766784 1450633895936 22% /run/media/cbrake/59b35dd4-954b-4568-9fa8-9e7df9c450fc
fuseblk 3561716731904 2638277668864 742441906176 78% /media/fileserver
ext2/ext3 984372027392 339508314112 594836836352 36% /run/media/cbrake/backup2
It would be handy if we could store filesystem as a tag, size/used/avail/% as fields, and mount point as text field.
We already have an array of points in a node – can we just make one array work?
The size/used/avail/% could easily be stored as different points. The text field
would store the mount point, which would tie all the stats for one partition
together. Then the question is how to represent the filesystem? With the added
Key field in proposal #2, we can now store the mount point as the key.
| Type | Key | Text | Value |
|---|---|---|---|
| filesystemSize | /home | 1243234 | |
| filesystemUsed | /home | 234222 | |
| filesystemType | /home | ext4 | |
| filesystemSize | /home | 1000000 | |
| filesystemUsed | /date | 10000 | |
| filesystemType | /home | btrfs |
Representing arrays
With the key field, we can represent arrays as a group of points, where key
defines the position in the array. For node points to be automatically decoded
into an array struct fields by the SIOT client manager, the key must be an
integer represented in string form.
One example where we do this is for selecting days of the week in schedule rule conditions. The key field is used to select the weekday. So we can have a series of points to represent Weekdays. In the below, Sunday is the 1st point set to 0, and Monday is the 2nd point, set to 1.
[]data.Point{
{
Type: "weekday",
Key: "0",
Value: 0,
},
{
Type: "weekday",
key: "1",
Value: 0,
},
}
In this case, the condition node has a series of weekday points with keys 0-6 to represent the days of the week.
The SIOT data.Decode is used by the client manager to initialize array fields in a client struct. The following assumptions are made:
- the value in the
keyfield is converted to an int and used as the index into the field array. - if there are missing array entries, they are filled with zero values.
- the data.MergePoints uses the same algorithm.
- if a point is inserted into the array or moved, all array points affected must
be sent. For example, if you have an array of length 20, and you insert a new
value at the beginning, then all 21 points must to be sent. This can have
implications for rules or any other logic that use the Point
keyfield.
This does not have perfect CRDT properties, but typically these arrays are generally small and are only modified in one place.
If you need more advanced functionality, you can bypass the data Decode/Merge functions and process the points manually and then use any algorithm you want to process them.
Point deletions
To date, we’ve had no need to delete points, but it may be useful in the future.
Consider the following sequence of point changes:
- t1: we have a point
- t2: A deletes the point
- t3: B concurrently change the point value
The below table shows the point values over time with the current point merge algorithm:
| Time | Value | Tombstone |
|---|---|---|
| t1 | 10 | 0 |
| t2 | 10 | 1 |
| t3 | 20 | 0 |
In this case, the point becomes undeleted because the last write wins (LWW). Is this a problem? What is the desired behavior? A likely scenario is that a device will be continually sending value updates and a user will make a configuration change in the portal that deletes a point. Thus it seems delete changes should always have precedence. However, with the last write wins (LWW) merge algorithm, the tombstone value could get lost. It may make sense to:
- make the tombstone value an int
- only increment it
- when merging points, the highest tombstone value wins
- odd value of tombstone value means point is deleted
Thus the tombstone value is merged independently of the timestamp and thus is always preserved, even if there concurrent modifications.
The following table shows the values with the modified point merge algorithm.
| Time | Value | Tombstone |
|---|---|---|
| t1 | 10 | 0 |
| t2 | 10 | 1 |
| t3 | 20 | 1 |
Duration, Min, Max
The current Point data type has Duration, Min, and Max fields. This is used for when a sensor value is averaged over some period of time, and then reported. The Duration, Min, Max fields are useful for describing what time period the point was obtained, and what the min/max values during this period were.
Representing maps
In the file system metrics example below, we would like to store a file system type for a particular mount type. We have 3 pieces of information:
data.Point {
Type: "fileSystem",
Text: "/media/data/",
????: "ext4",
}
Perhaps we could add a key field:
data.Point {
Type: "fileSystem",
Key: "/media/data/",
Text: "ext4",
}
The Key field could also be useful for storing the mount point for other
size/used, etc points.
making use of common algorithms and visualization tools
A simple point type makes it very nice to write common algorithms that take in points, and can always assume the value is in the value field. If we store multiple values in a point, then the algorithm needs to know which point to use.
If an algorithm needs multiple values, it seems we could feed in multiple point types and discriminated by point type. For example, if an algorithm used to calculate % of a partition used could take in total size and used, store each, and the divide them to output %. The data does not necessarily need to live in the same point. Could this be used to get rid of the min/max fields in the point? Could these simply be separate points?
- Having min/max/duration as separate points in influxdb should not be a problem for graphing – you would simply qualify the point on a different type vs selecting a different field.
- if there is a process that is doing advanced calculations (say taking the numerical integral of flow rate to get total flow), then this process could simply accumulate points and when it has all the points for a timestamp, then do the calculation.
Schema changes and distributed synchronization
A primary consideration of Simple IoT is easy and efficient data synchronization and easy schema changes.
One argument against embedded maps in a point is that adding these maps would likely increase the possibility of schema version conflicts between versions of software because points are overwritten. Adding maps now introduces a schema into the point that is not synchronized at the key level. There will also be a temptation to put more information into point maps instead of creating more points.
With the current point scheme, it is very easy to synchronize data, even if there are schema changes. All points are synchronized, so one version can write one set of points, and another version another, and all points will be sync’d to all instances.
There is also a concern that if two different versions of the software use different combinations of field/value keys, there could be information lost. The simplicity and ease of merging Points into nodes is no longer simple. As an example:
Point {
Type: "motorPIDConfig",
Values: {
{"P": 23},
{"I": 0.8},
{"D": 200},
},
}
If an instance with an older version writes a point that only has the “P” and “I” values, then the “D” value would get lost. We could merge all maps on writes to prevent losing information. However if we have a case where we have 3 systems:
Aold -> Bnew -> Cnew
If Aold writes an update to the above point, but only has P,I values, then this point is automatically forwarded to Bnew, and then Bnew forwards it to Cnew. However, Bnew may have had a copy with P,I,D values, but the D is lost when the point is forwarded from Aold -> Cnew. We could argue that Bnew has previously synchronized this point to Cnew, but what if Cnew was offline and Aold sent the point immediately after Cnew came online before Bnew synchronized its point.
The bottom line is there are edge cases where we don’t know if the point map data is fully synchronized as the map data is not hashed. If we implement arrays and maps as collections of points, then we can be more sure everything is synchronized correctly because each point is a struct with fixed fields.
Is there any scenario where we need multiple tags/labels on a point?
If we don’t add maps to points, the assumption is any metadata can be added as additional points to the containing node. Will this cover all cases?
Is there any scenario where we need multiple values in a point vs multiple points?
If we have points that need to be grouped together, they could all be sent with the same timestamp. Whatever process is using the points could extract them from a timeseries store and then re-associate them based on common timestamps.
Could duration/min/max be sent as separate points with the same timestamp instead of extra fields in the point?
The NATS APIs allow you to send multiple points with a message, so if there is ever a need to describe data with multiple values (say min/max/etc), these can simply be sent as multiple points in one message.
Is there any advantage to flat data structures?
Flat data structures where the fields consist only of simple types (no nested objects, arrays, maps, etc). This is essentially what tables in a relational database are. One advantage to keeping the point type flat is it would map better into a relational database. If we add arrays to the Point type, then it will not longer map into a single relational database table.
Design
Original Point Type
type Point struct {
// ID of the sensor that provided the point
ID string `json:"id,omitempty"`
// Type of point (voltage, current, key, etc)
Type string `json:"type,omitempty"`
// Index is used to specify a position in an array such as
// which pump, temp sensor, etc.
Index int `json:"index,omitempty"`
// Time the point was taken
Time time.Time `json:"time,omitempty"`
// Duration over which the point was taken. This is useful
// for averaged values to know what time period the value applies
// to.
Duration time.Duration `json:"duration,omitempty"`
// Average OR
// Instantaneous analog or digital value of the point.
// 0 and 1 are used to represent digital values
Value float64 `json:"value,omitempty"`
// Optional text value of the point for data that is best represented
// as a string rather than a number.
Text string `json:"text,omitempty"`
// statistical values that may be calculated over the duration of the point
Min float64 `json:"min,omitempty"`
Max float64 `json:"max,omitempty"`
}
Proposal #1
This proposal would move all the data into maps.
type Point struct {
ID string
Time time.Time
Type string
Tags map[string]string
Values map[string]float64
TextValues map[string]string
}
The existing min/max would just become fields. This would map better into influxdb. There would be some redundancy between Type and Field keys.
Proposal #2
type Point struct {
// The 1st three fields uniquely identify a point when receiving updates
Type string
Key string
// The following fields are the values for a point
Time time.Time
(removed) Index float64
Value float64
Text string
Data []byte
// Metadata
Tombstone int
}
Updated 2023-06-13: removed the Index field. We will use the Key field for
array indices.
Notable changes from the first implementation:
- removal of the
IDfield, as any ID information should be contained in the parent node. TheIDfield is a legacy from 1-wire setups where we represented each 1-wire sensor as a point. However, it seems now each 1-wire sensor should have its own node. - addition of the
Keyfield. This allows us to represent maps in a node, as well as add extra identifying information for a point. - the
Pointis now identified in the merge algorithm using theTypeandKey. Before, theID,Type, andIndexwere used. - the
Datafield is added to give us the flexibility to store/transmit data that does not fit in a Value or Text field. This should be used sparingly, but gives us some flexibility in the future for special cases. This came out of some comments in an Industry 4.0 community – basically types/schemas are good in a communication standard, as long as you also have the capability to send a blob of data to handle all the special cases. This seems like good advice. - the
Tombstonefields is added as anintand is always incremented. Odd values ofTombstonemean the point was deleted. When merging points, the highest tombstone value always wins.
Decision
Going with proposal #2 – we can always revisit this later if needed. This has minimal impact on the existing code base.
Objections/concerns
(Some of these are general to the node/point concept in general)
- Q: with the point datatype, we lose types
- A: in a single application, this concern would perhaps be a high priority, but in a distributed system, data synchronization and schema migrations must be given priority. Typically these collections of points are translated to a type by the application code using the data, so any concerns can be handled there. At least we won’t get JS undefined crashes as Go will fill in zero values.
- Q: this will be inefficient converting points to types
- A: this does take processing time, but this time is short compared to the network transfer times from distributed instances. Additionally, applications can cache nodes they care about so they don’t have to translate the entire point array every time they use a node. Even a huge IoT system has a finite # of devices that can easily fit into memory of modern servers/machines.
- Q: this seems crude not to have full featured protobuf types with all the
fields explicitly defined in protobuf. Additionally, can’t protobuf handle
type changes elegantly?
- A: protobuf can handle field additions and removal but we still have the edge cases where a point is sent from an old version of software that does not contain information written by a newer versions. Also, I’m not sure it is a good idea to have application specific type fields defined in protobuf, otherwise, you have a lot of work all along the communication chain to rebuild everything every time anything changes. With a generic types that rarely have to change, your core infrastructure can remain stable and any features only need to touch the edges of the system.
- Q: with nodes and points, we can only represent a type with a single level of
fields
- A: this is not quite true, because with the key/index fields, we can now have array and map fields in a node. However, the point is taken that a node with its points cannot represent a deeply nested data structure. However, nodes can be nested to represent any data structure you like. This limitation is by design because otherwise synchronization would be very difficult. By limiting the complexity of the core data structures, we are making synchronization and storage very simple. The tradeoff is a little more work to marshall/unmarshall node/point data structures into useful types in your application. However, marshalling code is easy compared to distributed systems, so we need to optimize the system for the hard parts. A little extra typing will not hurt anyone, and tooling could be developed if needed to assist in this.
Generic core data structures also opens up the possibility to dynamically extend the system at run time without type changes. For instance, the GUI could render new nodes it has never seen before by sending it configuration nodes with declarative instructions on how to display the node. If core types need to change to do this type of thing, we have no chance at this type of intelligent functionality.
Consequences
Removing the Min/Max/Duration fields should not have any consequences now as I don’t think we are using these fields yet.
Quite a bit of code needs to change to remove ID and add Key to code using points.
Additional Notes/Reference
We also took a look at how to resolve loops in the node tree:
https://github.com/simpleiot/simpleiot/issues/294
This is part of the verification to confirm our basic types are robust and have adequate CRDT properties.
Authorization
- Author: Blake Miner
- Issue: https://github.com/simpleiot/simpleiot/issues/268
- PR / Discussion: https://github.com/simpleiot/simpleiot/pull/283
- Status: Brainstorming
Problem
SIOT currently does not prevent unauthorized NATS clients from connecting and publishing / subscribing. Presently, any NATS client with access to the NATS server connection can read and write any data over the NATS connection.
Discussion
This document describes a few mechanisms for how to implement authentication and authorization mechanisms within Simple IoT.
Current Authentication Mechanism
Currently, SIOT supports upstream connections through the use of upstream nodes. The connection to the upstream server can be authenticated using a simple NATS auth token; however, all NATS clients with knowledge of the auth token can read / write any data over the NATS connection. This will not work well for a multi-tenant application or applications where user access must be closely controlled.
Similarly, web browsers can access the NATS API using the WebSocket library, but since they act as another NATS client, no additional security is provided; browsers can read / write all data over the NATS connection.
Proposal
NATS supports decentralized user authentication and authorization using NKeys and JSON Web Tokens (JWTs). While robust, this authentication and authorization mechanism is rather complex and confusing; a detailed explanation follows nonetheless. The end goal is to dynamically add NATS accounts to the NATS server because publish / subscribe permissions of NATS subjects can be tied to an account.
Background
Each user node within SIOT will be linked to a dynamically created NATS account (on all upstream nodes); each account is generated when the user logs in. Only a single secret is stored in the root node of the SIOT tree.
NATS has a public-key signature system based on Ed25519. These keypairs are called NKeys. Put simply, NKeys allow one to cryptographically sign and verify JWTs. An NKey not only consists of a Ed25519 private key / seed, but it also contains information on the “role” of the key. In NATS, there are three primary roles: operators, accounts, and users. In SIOT, there is one operator for a given NATS server, and there is one account for each user node.
Start-up
When the SIOT server starts, an NKey for the operator role is loaded from a
secret stored as a point in the root node of the tree. This point is always
stripped away when clients request the root node, so it’s never transmitted over
a NATS connection. Once the NATS server is running, SIOT will start an internal
NATS client and connect to the local NATS server. This internal client will
authenticate to the NATS server with a superuser, whose account has full
permissions to publish and subscribe to all subjects. Unauthenticated NATS
clients only have permission to publish to authsubject and listen for a
reply.
Authentication / Login
External NATS clients (including web browsers over WebSockets) must first log
into the NATS server anonymously (using the auth token if needed) and send a
request to the auth subject with the username and password of a valid user
node. The default username is admin, and the default password is admin. The
internal NATS client will subscribe to requests on the auth subject, and if
the username / password is correct, it will respond with a user NKey and user
JWT Token, which are needed to login. The user JWT token will be issued and
signed by the account NKey, and the account NKey will be issued and signed by
the operator NKey. The NATS connection will then be re-established using the
user JWT and signing a server nonce with the user’s NKey.
JWT expiration should be a configurable SIOT option and default to 1 hour.
Optionally, when the user JWT token is approaching its expiration, the NATS
client can request re-authenticate using the auth subject and reconnect using
the new user credentials.
Storing NKeys
As discussed above, in the root node, we store the seed needed to derive the operator NKey. For user nodes, account and user NKeys are computed as-needed from the node ID, the username, and the password.
Authorization
An authenticated user will have publish / subscribe access to the subject space
of $nodeID.> where $nodeID is the node ID for the authenticated user. The
normal SIOT NATS API will work the same as normal with two notable exceptions:
- The API subjects are prepended with
$nodeID. - The “root” node is remapped to the set of parents of the logged in user node
Examples
Example #1
Imagine the following a SIOT node tree:
- Root (Device 82ad…28ae)
- Power Users (Group b723…008d)
- Temperature Sensor (Device 2820…abdc)
- Humidity Sensor (Device a89f…eda9)
- Blake (User ab12…ef22)
- Admin (User 920d…ab21)
In this case, logging in as “Blake” would reveal the following tree with a single root node:
- Power Users (Group b723…008d)
- Temperature Sensor (Device 2820…abdc)
- Humidity Sensor (Device a89f…eda9)
- Blake (User ab12…ef22)
To get points of the humidity sensor, one would send a request to this subject:
ab12...ef22.p.a89f...eda9.
Example #2
Imagine the following a SIOT node tree:
- Root (Device 82ad…28ae)
- Temperature Sensor (Device 2820…abdc)
- Blake (User ab12…ef22)
- Humidity Sensor (Device a89f…eda9)
- Blake (User ab12…ef22)
- Admin (User 920d…ab21)
- Temperature Sensor (Device 2820…abdc)
In this case, logging in as “Blake” would reveal the following tree with two root nodes:
- Temperature Sensor (Device 2820…abdc)
- Blake (User ab12…ef22)
- Humidity Sensor (Device a89f…eda9)
- Blake (User ab12…ef22)
To get points of the humidity sensor, one would send a request to this subject:
ab12...ef22.p.a89f...eda9.
Implementation Notes
// Note: JWT issuer and subject must match an NKey public key
// Note: JWT issuer and subject must match roles depending on the claim NKeys
import (
"github.com/nats-io/jwt/v2"
"github.com/nats-io/nkeys"
"github.com/nats-io/nats-server/v2/server"
)
// Example code to start NATS server
func StartNatsServer(o Options) {
op, err := nkeys.CreateOperator()
if err != nil {
log.Fatal("Error creating NATS server: ", err)
}
pubKey, err := op.PublicKey()
if err != nil {
log.Fatal("Error creating NATS server: ", err)
}
acctResolver := server.MemAccResolver{}
opts := server.Options{
Port: o.Port,
HTTPPort: o.HTTPPort,
Authorization: o.Auth,
// First we trust all operators
// Note: DO NOT USE conflicting `TrustedKeys` option
TrustedOperators: []{jwt.NewOperatorClaims(pubKey)},
AccountResolver: acctResolver,
}
}
// Create an Account
acct, err := nkeys.CreateAccount()
if err != nil {
log.Fatal("Error creating NATS account: ", err)
}
pubKey, err := acct.PublicKey()
if err != nil {
log.Fatal("Error creating NATS account: ", err)
}
claims := jwt.NewAccountClaims{pubKey}
claims.DefaultPermissions = Permissions{
// Note: subject `_INBOX.>` allowed for all NATS clients
// Note: subject publish on `auth` allowed for all NATS clients
Pub: Permission{
Allow: StringList([]string{userNodeID+".>"}),
},
Sub: Permission{
Allow: StringList([]string{userNodeID+".>"}),
},
}
claims.Issuer = opPubKey
claims.Name = userNodeID
// Sign the JWT with the operator NKey
jwt, err := claims.Encode(op)
if err != nil {
log.Fatal("Error creating NATS account: ", err)
}
acctResolver.Store(userNodeID, jwt)
Node Lifecycle
- Author: Cliff Brake, last updated: 2022-02-16
- PR/Discussion:
- Status: discussion
Context
In the process of implementing a feature to duplicate a node tree, several problems have surfaced related to the lifecycle of creating and updating nodes.
Node creation (< 0.5.0)
- if a point was sent and node did not exist, SIOT created a “device” node as a child of the root node with this point. This was based on this initial use of SIOT with 1-wire devices.
- there is also a feature where if we send a point to a Device node that does not have an upstream path to root, or that path is tombstoned, we create this path. This ensures that we don’t have orphaned device nodes in an upstream if they are still active. This happens to the root node on clear startup.
- by the user in the UI – Http API,
/v1/nodesPOST, accepts a NodeEdge struct and then sends out node points and then edge points via NATs to create the node. - node is sent first, then the edge
The creation process for a node involves:
- sending all the points of a node including a meta point with the node type.
- sending the edge points of a node to describe the upstream connection
There are two problems with this:
- When creating a node, we send all the node points, then the edge points. However this can create an issue in that an upstream edge for a device node does not exist yet, so in a multi-level upstream configuration A->B->C, if B is syncing to C for the first time, multiple instances of A will be created on C.
- If a point is sent for a node that does not exist, a new device node will be created.
An attempt was made to switch the sending edge points of new nodes before node points, however this created other issues (this was some time ago, so don’t recall exactly what they were).
Node creation (>= 0.5.0)
With the switch to a SQLite store, a lot of code was rewritten, and in the process we changed the order of creating nodes to:
- send the edge points first
- then send node points
(See the SendNode() function).
discussion
Sending node and edge points separately for new nodes creates an issue in that these don’t happen in one communication transaction, so there is a period of time between the two where the node state is indeterminate. Consideration was given to adding a NATS endpoint to create nodes where everything could be sent at once. However, this is problematic in that now there is another NATS subject for everyone to listen to and process, rather than just listening for new points. It seems less than ideal to have multiple subjects that can create/modify node points.
It seems at this point we can probably deprecate the feature to create new devices nodes based on a single point. This will force new nodes to be explicitly created. This is probably OK as new nodes are created in several ways:
- by the user in the UI
- by the upstream sync mechanism – if the hash does match or a node does not exist upstream, it is sent. This is continuously checked so if a message does not succeed, it will eventually get resent.
- plug-n-play discovery mechanisms that detect new devices and automatically populate new nodes. Again, it is not a big deal if a message gets lost as the discovery mechanism will continue to try to create the new device if it does not find it.
Sending edge before parents can be problematic for things like the client manager that might be listening for tombstone points to detect node creation/deletion. (Why is this???)
Decision
Consequences
Time storage/format considerations
- Author: Cliff Brake, last updated: 2023-02-11
- PR/Discussion:
- Status: accepted
Contents
Problem
How can we store timestamps that are:
- efficient
- high resolution (ns)
- portable
- won’t run out of time values any time soon
We have multiple domains:
- Go
- MCU code
- Browser (ms resolution)
- SQLite
- Protbuf
Two questions:
- How should we store timestamps in SQLite?
- How should we transfer timestamps over the wire (typically protobuf)?
Context
We currently use Go timestamps in Go code, and protobuf timestamps on the wire.
Reference/Research
Browsers
Browsers limit time resolution to MS for security reasons.
64-bit nanoseconds
2 ^ 64 nanoseconds is roughly ~ 584.554531 years.
https://github.com/jbenet/nanotime
NTP
For NTP time, the 64bits are broken in to seconds and fraction of seconds. The top 32 bits is the seconds. The bottom 32 bits is the fraction of seconds. You get the fraction by dividing the fraction part by 2^32.
Linux
64-bit Linux systems are using 64bit timestamps (time_t) for seconds, and 32-bit systems are switching to 64-bit to avoid the 2038 bug.
The Linux clock_gettime() function uses the following datatypes:
struct timeval {
time_t tv_sec;
suseconds_t tv_usec;
};
struct timespec {
time_t tv_sec;
long tv_nsec;
};
Windows
Windows uses a 64-bit value representing the number of 100-nanosecond intervals since January 1, 1601 (UTC).
Go
The Go Time type is fairly intelligent as it uses Montonic time when possible and falls back to wall clock time when needed:
https://pkg.go.dev/time
If Times t and u both contain monotonic clock readings, the operations t.After(u), t.Before(u), t.Equal(u), and t.Sub(u) are carried out using the monotonic clock readings alone, ignoring the wall clock readings. If either t or u contains no monotonic clock reading, these operations fall back to using the wall clock readings.
The Go Time type is fairly clever:
type Time struct {
// wall and ext encode the wall time seconds, wall time nanoseconds,
// and optional monotonic clock reading in nanoseconds.
//
// From high to low bit position, wall encodes a 1-bit flag (hasMonotonic),
// a 33-bit seconds field, and a 30-bit wall time nanoseconds field.
// The nanoseconds field is in the range [0, 999999999].
// If the hasMonotonic bit is 0, then the 33-bit field must be zero
// and the full signed 64-bit wall seconds since Jan 1 year 1 is stored in ext.
// If the hasMonotonic bit is 1, then the 33-bit field holds a 33-bit
// unsigned wall seconds since Jan 1 year 1885, and ext holds a
// signed 64-bit monotonic clock reading, nanoseconds since process start.
wall uint64
ext int64
// loc specifies the Location that should be used to
// determine the minute, hour, month, day, and year
// that correspond to this Time.
// The nil location means UTC.
// All UTC times are represented with loc==nil, never loc==&utcLoc.
loc *Location
}
Go provides a UnixNano() function that converts a Timestamp to nanoseconds elapsed since January 1, 1970 UTC.
To go the other way, Go provides a
UnixMicro() function to convert
microseconds since 1970 to a timestamp. The
source code
could probably be modified to create a UnixNano() function.
// UnixMicro returns the local Time corresponding to the given Unix time,
// usec microseconds since January 1, 1970 UTC.
func UnixMicro(usec int64) Time {
return Unix(usec/1e6, (usec%1e6)*1e3)
}
// Unix returns the local Time corresponding to the given Unix time,
// sec seconds and nsec nanoseconds since January 1, 1970 UTC.
// It is valid to pass nsec outside the range [0, 999999999].
// Not all sec values have a corresponding time value. One such
// value is 1<<63-1 (the largest int64 value).
func Unix(sec int64, nsec int64) Time {
if nsec < 0 || nsec >= 1e9 {
n := nsec / 1e9
sec += n
nsec -= n * 1e9
if nsec < 0 {
nsec += 1e9
sec--
}
}
return unixTime(sec, int32(nsec))
}
Protobuf
The Protbuf time format also has sec/ns sections:
message Timestamp {
// Represents seconds of UTC time since Unix epoch
// 1970-01-01T00:00:00Z. Must be from 0001-01-01T00:00:00Z to
// 9999-12-31T23:59:59Z inclusive.
int64 seconds = 1;
// Non-negative fractions of a second at nanosecond resolution. Negative
// second values with fractions must still have non-negative nanos values
// that count forward in time. Must be from 0 to 999,999,999
// inclusive.
int32 nanos = 2;
}
MQTT
Note sure yet if MQTT defines a timestamp format.
Sparkplug does:
timestamp
- This is the timestamp in the form of an unsigned 64-bit integer representing the number of milliseconds since epoch (Jan 1, 1970). It is highly recommended that this time is in UTC. This timestamp is meant to represent the time at which the message was published
CRDTs
LWW (last write wins) CRDTs often use a logical clock. crsql uses a 64-bit logical clock.
Do we need nanosecond resolution?
Many IoT systems only support MS resolution. However, this is sometimes cited as a deficiency in applications where higher resolution is needed (e.g. power grid).
Decision
- NATS messages
- stick with standard protobuf Time definition in NATS packets
- this is most compatible with all the protobuf language support out there
- Database
- switch to single time field that contains NS since Unix epoch
- this is simpler and allows us to easily do comparisons on the field
objections/concerns
Consequences
Migration is required for database, but should be transparent to the user.
Time Validation
- Author: Cliff Brake
- PR/Discussion:
- Status: discussion
Contents
Problem
To date, SIOT has been deployed to systems with RTCs and solid network connections, so time is fairly stable, thus this has not been a big concern. However, we are looking to deploy to edge systems, some with cellular modem connections and some without a battery backed RTC, so they may boot without a valid time.
SIOT is very dependent on data having valid timestamps. If timestamps are not correct, the following problems may occur:
- old data may be preferred over newer data in the point CRDT merge algorithm
- data stored in time series databases may have the wrong time stamps
Additionally, there are edge systems that don’t have a real-time clock and power up with an invalid time until a NTP process gets the current time.
We may need some systems to operate (run rules, etc) without a valid network connection (offline) and valid time.
Context/Discussion
Clients affected
- db (InfluxDB driver)
- sync (sends data upstream)
- store (not sure ???)
The db and sync clients should not process points (or perhaps buffer them until) until we are sure the system has a valid time. How does it get this information? Possibilities include:
- creating a broadcast or other special message subject that clients can optionally listen to. Perhaps the NTP client can send this message.
- synchronization may be a problem here if NTP client sends messages before a client has started.
- query for system state, and NTP sync status could be a field in this state.
- should this be part of the root device node?
- or a special hard-coded message?
- it would be useful to track system state as a standard point so it gets synchronized and stored in influxdb, therefore as part of the root node would be useful, or perhaps the NTP node.
Offline operation
System must function when offline without valid time. Again, for the point merge algorithm to work correctly, timestamps for new points coming into the store must be newer than what is currently stored. There are two possible scenarios:
- Problem: system powers up with old time, and points in DB have newer time.
- Solution: if we don’t have a valid NTP time, then set system time to something later than the newest point timestamp in the store.
- Problem: NTP sets the time “back” and there are newer points in the DB.
- Solution: when we get a NTP time sync, verify it is not significantly earlier than the latest point timestamp in the system. If it is, update the point timestamps in the DB that are newer than the current time with the current time - 1yr. This ensures that settings upstream (which are likely newer than the edge device) will update the points in the edge device. This is not perfect, but if probably adequate for most systems.
We currently don’t queue data when an edge device is offline. This is a different concern which we will address later.
The SIOT synchronization and point merge algorithm are designed to be simple and bandwidth efficient (works over Cat-M/NBIOT modems). There are design trade-offs. It is not a full-blown replicated, log-based database that will work correctly in every situation. It is designed so that changes can be made in multiple locations while disconnected and when a connection is resumed, that data is merged intelligently. Typically, configuration changes are made at the portal, and sensor data is generated at the edge, so this works well in practice. When in doubt, we prioritize changes made on the upstream (typically cloud instance), as that is the most user accessible system and is where most configuration changes will be made. Sensor data is updated periodically, so that will automatically get refreshed typically within 15m max. The system works best when we have a valid time at every location so we advise ensuring reliable network connections for every device, and at a minimum have a reliable battery backed RTC in every device.
Tracking the latest point timestamp
It may make sense to write the latest point timestamp to the store meta table.
Syncing time from Modem or GPS
Will consider in future. Assume a valid network connection to NTP server for now.
Tracking events where time is not correct
It would be very useful to track events at edge devices where time is not correct and it requires a big jump to be corrected.
TODO: how can we determine this? From systemd-timedated logs?
This information could be used to diagnose when a RTC battery needs replaced, etc.
Verify time matches between synchronized instances
A final check that may be useful is to verify time between synchronized instances are relatively close. This is a final check to ensure the sync algorithm does not wreak havoc between systems, even if NTP is lying.
Reference/Research
NTP
- https://wiki.archlinux.org/title/systemd-timesyncd
timedatectl statusproduces following output:
Local time: Thu 2023-06-01 18:22:23 EDT
Universal time: Thu 2023-06-01 22:22:23 UTC
RTC time: Thu 2023-06-01 22:22:23
Time zone: US/Eastern (EDT, -0400)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
There is a systemd-timedated D-Bus API.
Decision
what was decided.
objections/concerns
Consequences
what is the impact, both negative and positive.
Additional Notes/Reference
Time storage in rule schedules
- Author: Cliff Brake, last updated: 2023-07-10
- PR/Discussion:
- Status: discussion
Problem
When storing times/dates in rule schedules, we store time as UTC, but this can be problematic when there is a time change. In once application, SIOT plays a chime at a certain time of day, but when time changes (daylight savings time), we need to adjust the time in the rule and this is easy to forget.
Context/Discussion
UTC was chosen as the storage format for the following reasons:
- it is universal – it always means the same thing everywhere
- typically in UI or reports, times are translated to users local times
- server and edge devices can operate in UTC without needing to worry about local time
- rules run on cloud instances have a common timebase to work from. In a highly distributed system, you may have device in one timezone trigger an action in another time zone.
However, must applications (building automation, etc.) run in a single location, and the loss or gain of an hour when the time changes is very inconvenient.
Reference/Research
Decision
what was decided.
objections/concerns
Consequences
what is the impact, both negative and positive.
Additional Notes/Reference
JetStream SIOT Store
- Author: Cliff Brake, last updated: 2024-01-24
- Status: discussion
Problem
SQLite has worked well as a SIOT store. There are a few things we would like to improve:
- Synchronization of history
- Currently, if a device or server is offline, only the latest state is transferred when connected. We would like all history that has accumulated when offline to be transferred once reconnected.
- We want history at the edge as well as cloud
- This allows us to use history at the edge to run more advanced algorithms like AI
- We currently have to re-compute hashes all the way to the root node anytime
something changes
- This may not scale to larger systems
- Is difficult to get right if things are changing while we re-compute hashes
- it requires some type of coordination between the distributed systems, which we currently don’t have.
Context/Discussion
The purpose of this document is to explore storing SIOT state in a NATS JetStream store. SIOT data is stored in a tree of nodes and each node contains an array of points. Note, the term “node” in this document represents a data structure in a tree, not a physical computer or SIOT instance. The term “instance” will be used to represent devices or SIOT instances.
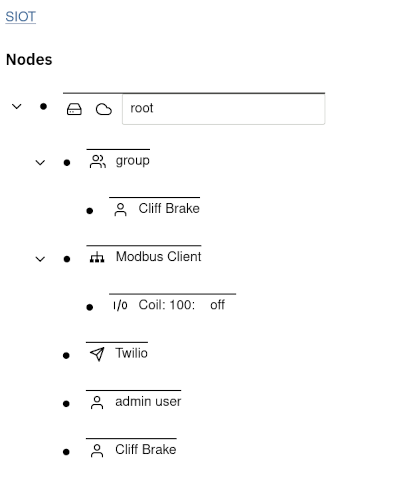
Nodes are arranged in a directed acyclic graph.
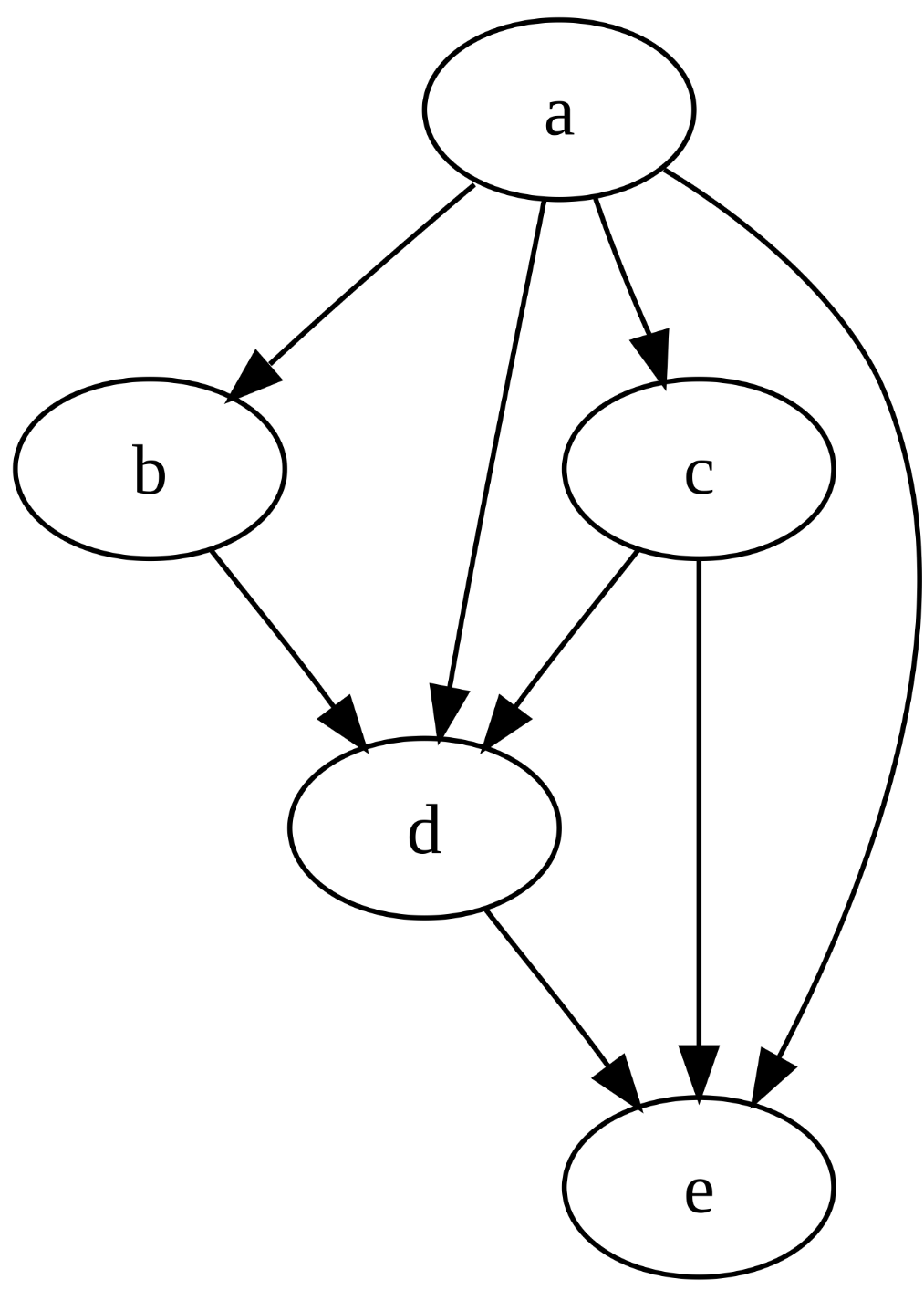
A subset of this tree is synchronized between various instances as shown in the below example:
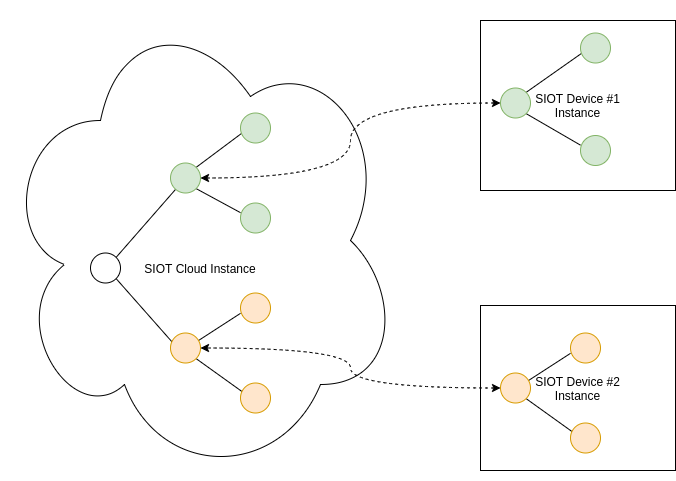
The tree topology can be as deep as required to describe the system. To date, only the current state of a node is synchronized and history (if needed) is stored externally in a time-series database like InfluxDB and is not synchronized. The node tree is an excellent data model for IoT systems.
Each node contains an array of points that represent the state of the node. The points contain a type and a key. The key can be used to describe maps and arrays. We keep points separate so they can all be updated independently and easily merged.
With JetStream, we could store points in a stream where the head of the stream represents the current state of a Node or collection of nodes. Each point is stored in a separate NATS subject.
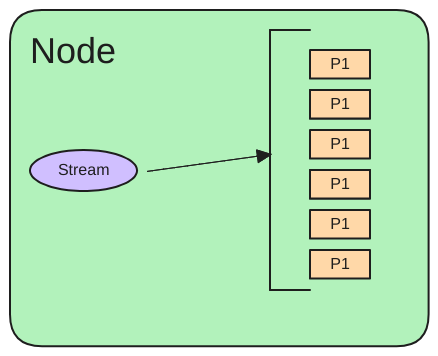
NATS JetStream is a stream-based store where every message in a stream is given a sequence number. Synchronization is simple in that if a sequence number does not exist on a remote system, the missing messages are sent.
NATS also supports leaf nodes (instances) and streams can be synchronized between hub and leaf instances. If they are disconnected, then streams are “caught up” after the connection is made again.
Several experiments have been run to understand the basic JetStream functionality in this repo.
- Storing and extracting points in a stream
- Using streams to store time-series data and measure performance
- Syncing streams between the hub and leaf instances
Advantages of JetStream
- JetStream is built into NATS, which we already embed and use.
- History can be stored in a NATS stream instead of externally. Currently, we use an external store like InfluxDB to store history.
- JetStream streams can be synchronized between instances.
- JetStream has various retention models so old data can automatically be dropped.
- Leverage the NATS AuthN/AuthZ features.
- JetStream is a natural extension of core NATS, so many of the core SIOT concepts are still valid and do not need to change.
Challenges with moving to JetStream
- Streams are typically synchronized in one direction. This is a challenge for SIOT as the basic premise is data can be modified in any location where a user/device has proper permissions. A user may change a configuration in a cloud portal or on a local touch-screen.
- Sequence numbers must be set by one instance, so you can’t have both a leaf and hub nodes inserting data into a single stream. This has benefits in that it is a very simple and reliable model.
- We are constrained by a simple message subject to label and easily query data. This is less flexible than an SQL database, but this constraint can also be an advantage in that it forces us into a simple and consistent data model.
- SQLite has a built-in cache. We would likely need to create our own with JetStream.
JetStream consistency model
From this discussion:
When the doc mentions immediate consistency, it is in contrast to eventual consistency. It is about how ‘writes’ (i.e. publishing a message to a stream).
JetStream is an immediately consistent distributed storage system in that every new message stored in the stream is done so in a unique order (when those messages reach the stream leader) and that the acknowledgment that the storing of the message has been successful only happens as the result of a RAFT vote between the NATS JetStream servers (e.g. 3 of them if replicas=3) handling the stream.
This means that when a publishing application receives the positive acknowledgement to it’s publication to the stream you are guaranteed that everyone will see that new message in their updates in the same order (and with the same sequence number and time stamp).
This ‘non-eventual’ consistency is what enables ‘compare and set’ (i.e. compare and publish to a stream) operations on streams: because there can only be one new message added to a stream at a time.
To map back to those formal consistency models it means that for writes, NATS JetStream is Linearizable.
Currently SIOT uses a more “eventually” consistent model where we used data structures with some light-weight CRDT proprieties. However, this has the disadvantage that we have to do things like hash the entire node tree to know if anything has changed. In a more static system where not much is changing, this works pretty well, but in a dynamic IoT system where data is changing all the time, it is hard to scale this model.
Message/Subject encoding
In the past, we’ve used the Point data structure. This has worked extremely well at representing reasonably complex data structures (including maps and arrays) for a node. Yet it has limitations and constraints that have proven useful it making data easy to store, transmit, and merge.
// Point is a flexible data structure that can be used to represent
// a sensor value or a configuration parameter.
// ID, Type, and Index uniquely identify a point in a device
type Point struct {
//-------------------------------------------------------
//1st three fields uniquely identify a point when receiving updates
// Type of point (voltage, current, key, etc)
Type string `json:"type,omitempty"`
// Key is used to allow a group of points to represent a map or array
Key string `json:"key,omitempty"`
//-------------------------------------------------------
// The following fields are the values for a point
// Time the point was taken
Time time.Time `json:"time,omitempty" yaml:"-"`
// Instantaneous analog or digital value of the point.
// 0 and 1 are used to represent digital values
Value float64 `json:"value,omitempty"`
// Optional text value of the point for data that is best represented
// as a string rather than a number.
Text string `json:"text,omitempty"`
// catchall field for data that does not fit into float or string --
// should be used sparingly
Data []byte `json:"data,omitempty"`
//-------------------------------------------------------
// Metadata
// Used to indicate a point has been deleted. This value is only
// ever incremented. Odd values mean point is deleted.
Tombstone int `json:"tombstone,omitempty"`
// Where did this point come from. If from the owning node, it may be blank.
Origin string `json:"origin,omitempty"`
}
With JetStream, the Typeand Key can be encoded in the message subject:
p.<node id>.<type>.<key>
Message subjects are indexed in a stream, so NATS can quickly find messages for any subject in a stream without scanning the entire stream (see discussion 1 and discussion 2).
Over time, the Point structure has been simplified. For instance, it used to
also have an Index field, but we have learned we can use a single Key field
instead. At this point it may make sense to simplify the payload. One idea is to
do away with the Value and Text fields and simply have a Data field. The
components that use the points have to know the data-type anyway to know if they
should use the Value or Textfield. In the past, Protobuf encoding was used
as we started with quite a few fields and provided some flexibility and
convenience. But as we have reduced the number of fields and two of them are now
encoded in the message subject, it may be simpler to have a simple encoding for
Time, Data, Tombstone, and Origin in the message payload. The code using
the message would be responsible for convert Data into whatever datatype is
needed. This would open up the opportunity to encode any type of payload in the
future in the Data field and be more flexible for the future.
Message payload:
Time(uint64)Tombstone(byte)OriginLen(byte)Origin(string)Data Type(byte)Data(length determined by the message length subtracted by the length of the above fields)
Examples of types:
- 0 - unknown or custom
- 1 - float (32, or 64 bit)
- 2 - int (8, 16, 32, or 64 bit)
- 3 - unit (8, 16, 32, or 65 bit)
- 4 - string
- 5 - JSON
- 6 - Protobuf
Putting Origin in the message subject will make it inefficient to query as you
will need to scan and decode all messages. Are there any cases where we will
need to do this? (this is an example where an SQL database is more flexible).
One solution would be to create another stream where the origin is in the
subject.
There are times when the current point model does not fit very well - for instance when sending a notification - this is difficult to encode in an array of points. I think in these cases encoding the notification data as JSON probably makes more sense and this encoding should work much better.
Can’t send multiple points in a message
In the past, it was common to send multiple points in a message for a node - for
instance when creating a node, or updating an array. However, with the type
and key encoded in the subject this will no longer work. What is the
implication for having separate messages?
- Will be more complex to create nodes
- When updating an array/map in a node, it will not be updated all at once, but over the time it takes all the points to come into the client.
- There is still value in arrays being encoded as points - for instance a relay devices that contains two relays. However, for configuration are we better served by encoding the struct in a the data field as JSON and updating it as an atomic unit?
UI Implications
Because NATS and JetStream subjects overlap, the UI could subscribe to the current state changes much as is done today. A few things would need to change:
- Getting the initial state could still use the
NATS
nodesAPI. However, theValueandTextfields might be merged intoData. - In the
p.<node id>subscription, theTypeandKeynow would come from the message subject.
Bi-Directional Synchronization
Bi-directional synchronization between two instances may be accomplished by having two streams for every node. The head of both incoming and outgoing streams is looked at to determine the current state. If points of the same type exist in both streams, the point with the latest timestamp wins. In reality, 99% of the time, one set of data will be set by the Leaf instance (ex: sensor readings) and another set of data will be set by the upstream Hub instance (ex: configuration settings) and there will be very little overlap.
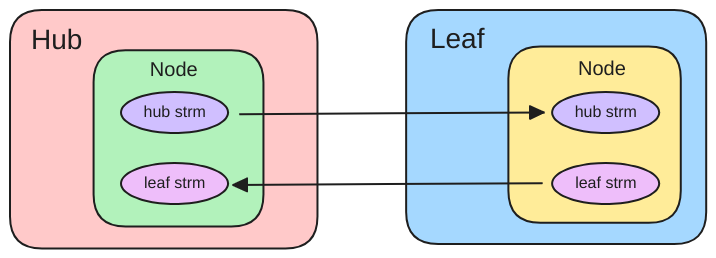
The question arises - do we really need bi-directional synchronization and the complexity of having two streams for every node? Every node includes some amount of configuration which can flow down from upstream instances. Additionally, many nodes are collecting data which needs to flow back upstream. So it seems a very common need for every node to have data flowing in both directions. Since this is a basic requirement, it does not seem like much of stretch to allow any data to flow in either stream, and then merge the streams at the endpoints where the data is used.
Does it make sense to use NATS to create merged streams?
NATS can source streams into an additional 3rd stream. This might be useful in that you don’t have to read two streams and merge the points to get the current state. However, there are several disadvantages:
- Data would be stored twice
- Data is not guaranteed to be in chronological order - the data would be inserted into the 3rd stream when it is received. So you would still have to walk back in history to know for sure if you had the latest point. It seems simpler to just read the head of two streams and compare them.
Timestamps
NATS JetStream messages store a timestamp, but the timestamp is when the message is inserted into the stream, not necessarily when the sample was taken. There can be some delay between the NATS client sending the message and the server processing it. Therefore, an additional high-resolution 64-bit timestamp is added to the beginning of each message.
Edges
Edges are used to describe the connections between nodes. Nodes can exist in
multiple places in the tree. In the below example, N2 is a child of both N1
and N3.
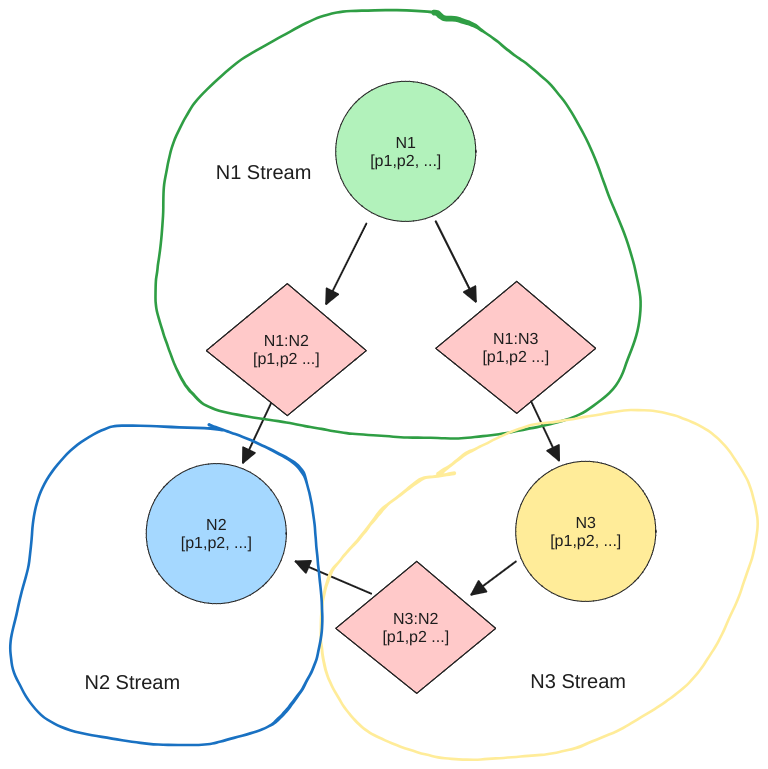
Edges currently contain the up and downstream node IDs, an array of points, and a node type. Putting the type in the edge made it efficient to traverse the tree by loading edges from a SQLite table and indexing the IDs and type. With JetStream it is less obvious how to store the edge information. SIOT regularly traverses up and down the tree.
- Down: to discover nodes
- Up: to propagate points to up subjects
Because edges contain points that can change over time, edge points need to be stored in a stream, much like we do the node points. If each node has its own stream, then the child edges for the node could be stored in the same stream as the node as shown above. This would allow us to traverse the node tree on startup and perhaps cache all the edges. The following subject can be used for edge points:
p.<up node ID>.<down node ID>.<type>.<key>
Again, this is very similar to the existing NATS API.
Two special points are present in every edge:
nodeType: defines the type of the downstream nodetombstone: set to true if the downstream node is deleted
One challenge with this model is much of the code in the SIOT uses a
NodeEdge data structure which includes a node and its parent edge. This
collection of data describes this instance of a node and is more useful from a
client perspective. However, NodeEdge’s are duplicated for every mirrored node
in the tree, so don’t really make sense from a storage and synchronization
perspective. This will likely become more clear after some implementation work.
NATS up.* subjects
In SIOT, we partition the system using the tree structure and nodes that listen
for messages (databases, messaging services, rules, etc.) subscribe to the
up.*stream of their parent node. In the below example, each group has it’s own
database configuration and the Db node only receives points generated in the
group it belongs to. This provides an opportunity for any node at any level in
the tree to listen to messages of another node, as long as:
- It is equal or higher in the structure
- Shares an ancestor.
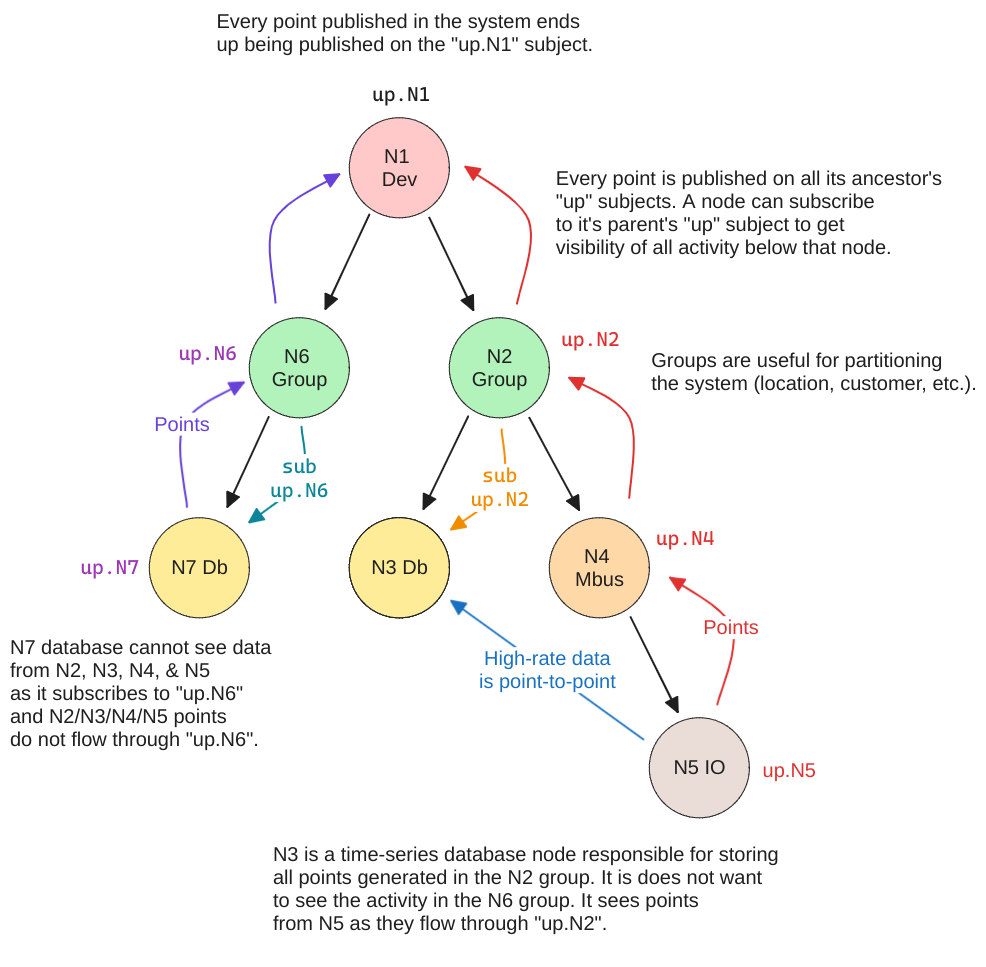
The use of “up” subjects would not have to change other than the logic that re-broadcasts points to “up” subjects would need to use the edge cache instead of querying the SQLite database for edges.
AuthN/AuthZ
Authorization typically needs to happen at device or group boundaries. Devices or users will need to be authorized. Users have access to all nodes in their parent group or device. If each node has its own stream, that will simplify AuthZ. Each device or user are explicitly granted permission to all the Nodes they have access to. If a new node is created that is a child of a node a user has permission to view, this new node (and the subsequent streams) are added to the list.
Are we optimizing the right thing?
Any time you move away from an SQL database, you should think long and hard about this. Additionally, there are very nice time-series database solutions out there. So we should have good reasons for inventing yet-another-database. However, mainstream SQL and Time-series databases all have one big drawback: they don’t support synchronizing subsets of data between distributed systems.
With system design, one approach is to order the problems you are solving by difficulty with the top of the list being most important/difficult, and then optimize the system to solve the hard problems first.
- Synchronizing subsets of data between distributed systems (including history)
- Be small and efficient enough to deploy at the edge
- Real-time response
- Efficient searching through history
- Flexible data storage/schema
- Querying nodes and state
- Arbitrary relationships between data
- Data encode/decode performance
The number of devices and nodes in systems SIOT is targeting is relatively small, thus the current node topology can be cached in memory. The history is a much bigger dataset so using a stream to synchronize, store, and retrieve time-series data makes a lot of sense.
On #7, will we ever need arbitrary relationships between data? With the node graph, we can do this fairly well. Edges contain points that can be used to further characterize the relationship between nodes. With IoT systems your relationships between nodes is mostly determined by physical proximity. A Modbus sensor is connected to a Modbus, which is connected to a Gateway, which is located at a site, which belongs to a customer.
On #8, the network is relatively slow compared to anything else, so if it takes a little more time to encode/decode data this is typically not a big deal as the network is the bottleneck.
With an IoT system, the data is primarily 1) sequential in time, and 2) hierarchical in structure. Thus, the streaming/tree approach still appears to be the best approach.
Questions
- How chatty is the NATS Leaf-node protocol? Is it efficient enough to use over low-bandwidth Cat-M cellular connections (~20-100Kbps)?
- Is it practical to have 2 streams for every node? A typical edge device may have 30 nodes, so this is 60 streams to synchronize. Is the overhead to source this many nodes over a leaf connection prohibitive?
- Would it make sense to create streams at the device/instance boundaries rather
than node boundaries?
- This may limit our AuthZ capabilities where we want to give some users access to only part of a cloud instance.
- How robust is the JetStream store compared to SQLite in events like power loss?
- Are there any other features of NATS/JetStream that we should be considering?
Experiments
Several proof-of-concept experiments have been run to prove the feasibility of this:
https://github.com/simpleiot/nats-exp
Decision
Implementation could be broken down into 3 steps:
- Message/subject encoding changes
- Switch store from SQLite to JetStream
- Use JetStream to sync between systems
objections/concerns
Consequences
What is the impact, both negative, and positive.
Additional Notes/Reference
ADR Title
- Author: NAME, last updated: DATE
- PR/Discussion:
- Status: discussion
Problem
What problem are we trying to solve?
Context/Discussion
background, facts surrounding this discussion.
Reference/Research
links to reference material that may be
Decision
what was decided.
objections/concerns
Consequences
what is the impact, both negative and positive.